 Luke.Du's blog
Luke.Du's blog
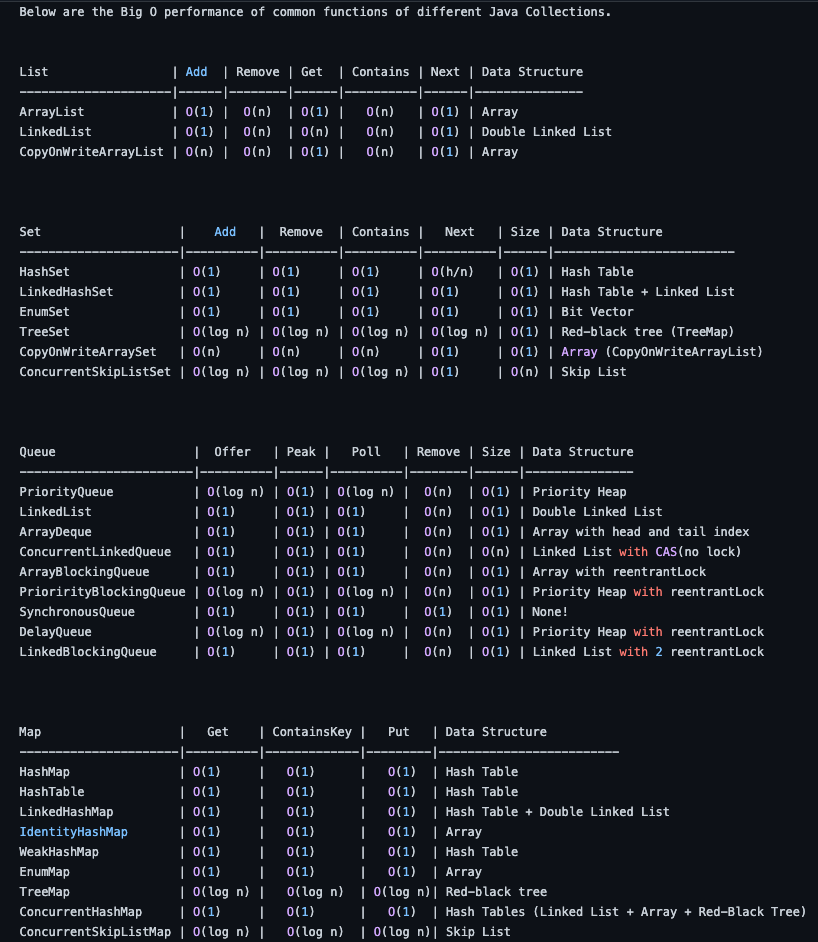
Collections data structure and their operations’ time complexity are important fundamental knowledge for becoming a better developer.
https://gist.github.com/ADU-21/3aa17ea810ad5725c94358eaa907ff7f
List
ArrayList
ArrayList is one of the List implementations built atop an array, which is able to dynamically grow and shrink as you add/remove elements. Elements could be easily accessed by their indexes starting from zero.
The default initial size of the array in ArrayList is 10, and the capacity doubled every time the maximum capacity is reached. For each operation’s time complexity:
- add() – takes O(1) time; however, worst-case scenario, when a new array has to be created and all the elements copied to it, it’s O(n)
- add(index, element) – on average runs in O(n) time
- get() – is always a constant time O(1) operation
- remove() – runs in linear O(n) time. We have to iterate the entire array to find the element qualifying for removal.
- indexOf() – also runs in linear time. It iterates through the internal array and checks each element one by one, so the time complexity for this operation always requires O(n) time.
- contains() – implementation is based on indexOf(), so it’ll also run in O(n) time.
LinkedList
LinkedList is a doubly-linked list implementation of the List and Deque interfaces. It implements all optional list operations and permits all elements (including null).
- add() – appends an element to the end of the list. It only updates a tail with O(1) constant-time complexity.
- add(index, element) – on average runs in O(n) time.
- get() – searching for an element takes O(n) time.
- remove(element) – to remove an element, we first need to find it. This operation is O(n).
- remove(index) – to remove an element by index, we first need to follow the links from the beginning; therefore, the overall complexity is O(n).
- contains() – also has O(n) time complexity
CopyOnWriteArrayList
A thread-safe variant of ArrayList in which all mutative operations (add, set, and so on) are implemented by making a fresh copy of the underlying array and having a lock on the operation. The reason is array is volatile, so we don’t have to add a lock on the read operation, to prevent read-while-writing and writing conflict, we should guarantee write operation is atomic, so we add a synchronized (lock) there, this is a good lock strategy for high frequently read and low frequently write scenario. The short come is to write is expensive.
- add() – Because we need to clone the array, the complexity is O(n), also
synchronizedwas applied here. - get() – read function apply to the original array, so it’s O(1)
- remove() – O(2n) = O(n) time, firstly find the index from the original array then remove it from copy.
- contains() – likewise, the complexity is O(n)
Fun fact about using extrinsic lock on a private object instead of intrisic locking: Basically it prevent attacker manipulate the system to trigger contention and deadlock by obtaining and indefinitely holding the intrinsic lock of an accessible class, consequently causing a denial of service (DoS).
Set
HashSet
HashSet implements the Set interface, backed by a hash table (actually a HashMap instance). It makes no guarantees as to the iteration order of the set and it’s not thread-safe. It permits the null element.
the add(), remove(), contains() and size() operations cost constant O(1) time thanks to the internal HashMap implementation.
LinkedHashSet
Hash table and linked list implementation of the Map interface, with predictable iteration order. It extends from HashMap class, the difference is it maintains a doubly-linked list running through all of its entries. This linked list defines the iteration ordering, which is normally the order in which keys were inserted into the map (insertion-order). Note that insertion order is not affected if a key is re-inserted into the map. This kind of map is well-suited to building LRU caches.
This class provides all of the optional Map operations, and permits null elements. Like HashMap, it provides constant-time O(1) performance for the basic operations ( add, contains and remove), assuming the hash function disperses elements properly among the buckets. Performance is likely to be just slightly below HashMap, due to the added expense of maintaining the linked list(in afterNodeAccess() afterNodeRemove()function, also O(1)), with one exception: Iteration over the collection-views of a LinkedHashMap requires time proportional to the size of the map, regardless of its capacity. Iteration over a HashMap is likely to be more expensive, requiring time proportional to its capacity.
EnumSet
Enum set is used when you want a collection of enums, the elements are represented internally as bit vectors. This representation is extremely compact and efficient way to implement Set. The space and time performance of this class should be good enough to allow its use as a high-quality, typesafe alternative to traditional int-based “bit flags.” Even bulk operations (such as containsAll and retainAll) should run very quickly if their argument is also an enum set.
This article talk about EnumSet is really good: https://www.cnblogs.com/swiftma/p/6044718.html
TreeSet
TreeSet is implemented on top of TreeMap, using Red-Black Tree(RBTree). RBTree is a Dynamic Balanced BST(Binary Search Tree), It will balance itself to make sure the height for the tree always be Log N, hence, the basic operations ( add, contains and remove) can be kept in O(LogN)
CopyOnWriteArraySet
A Set that uses an internal CopyOnWriteArrayList for all of its operations. The only difference is for add() Operation it uses addIfAbsent() function in CopyOnWriteArrayList Class, it first checks whether the element exists in the original array, if does, return false; otherwise, copy and updates array with the new element added.
the basic operations ( add, contains and remove) are same as CopyOnWriteArrayList O(N).
ConcurrentSkipListSet
Based on ConcurrentSkipListMap, ConcurrentSkipListMap is a replacement for TreeMap in concurrency scenario, it’s using CAS(Compare And Swap) so it’s lock free. Unlike TreeMap using RBTree, it uses SkipList for searching optimization.
This is an article about skipList: https://www.helloworld.net/p/2925102086
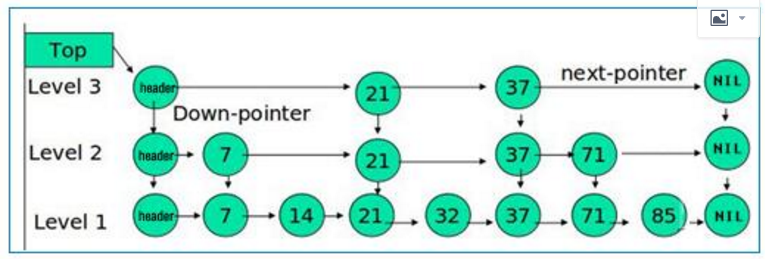
The search, add, remove function in skipList is same as binary search, so they’re O(logN), here is another article discribe how’s add/remove happen in skipList: https://www.cnblogs.com/yangming1996/p/8084819.html
Beware that, unlike in most collections, the size() method is NOT a constant-time operation. Because of the asynchronous nature of these sets, determining the current number of elements requires traversing them all to count them. Additionally, it is possible for the size to change during execution of this method, in which case the returned result will be inaccurate. Thus, this method is typically not very useful in concurrent applications.
Queue
PriorityQueue
A heap can customize comparator, so the offer() and poll() operations take O(logN), however, the remove() has to find the element from the array then remove it, it’s O(N) + O(logN) = O(N).
ArrayDeque
ArrayDeque is backed by an resizable array(2 when <64 otherwise 50% when filled) with head and tail indexes. It’s implemented as a double-ended queue where it maintains two pointers namely a head and a tail. It’s not thread-safe. Null elements are prohibited. This class is likely to be faster than Stack when used as a stack, and faster than LinkedList when used as a queue.
All basic function offer(), poll(), size() has O(1) complexity, for remove(), it require search in O(N), and O(1) for delete, so it’s O(N).
ConcurrentLinkedQueue
An unbounded thread-safe queue based on single-direction linked nodes. It was implemented in a non-blocked way by using CAS.
The offer() operation append element on tail of link, poll() get and remove from head, they’re both O(1) complexity.
The remove() has to find the element first then remove it, thos, the overall time complexity is O(N).
https://blog.csdn.net/qq_38293564/article/details/80798310
ArrayBlockingQueue
A bounded blocking queue backed by an array. This queue orders elements FIFO (first-in-first-out). Once created, the capacity cannot be changed, and it’s using a ReentrantLock to protect every operation including enQueue, deQueue, and peek. Attempts to put an element into a full queue will result in the operation blocking; attempts to take an element from an empty queue will similarly block.
ArrayBlockingQueue keeps tracking of putIndex and takenIndex , when index reach to array.length, start from 0, so the offer() and poll() TC is O(1), as well as size().
And it has notEmpty for block take operation when queue is empty, and notFull condiction to block put operationwhen queue is full. A naive implement would be like:
1 | class TaskQueue { |
PriorityBlockingQueue
A PriorityQueue implemented BlockingQueue interface. It’s using ReentrantLock to control thread synchronization, using CAS to control size growth.
So every operation’s TC is same as PriorityQueue, the only difference is all public function has a lock.
https://developer.aliyun.com/article/577859
SynchronousQueue
A blocking queue in which each insert operation must wait for a corresponding remove operation by another thread, and vice versa. A synchronous queue does not have any internal capacity, not even a capacity of one. You cannot peek at a synchronous queue because an element is only present when you try to remove it; you cannot insert an element (using any method) unless another thread is trying to remove it; you cannot iterate as there is nothing to iterate. The head of the queue is the element that the first queued inserting thread is trying to add to the queue; if there is no such queued thread then no element is available for removal and poll() will return null. For purposes of other Collection methods (for example contains), a SynchronousQueue acts as an empty collection. This queue does not permit null elements.
The offer() and poll() operations are taking O(1), the remove(), peek(), size() will do nothing but response instantly.
This queue is mostly been used for ThreadPoolExecutor, to provide the best throughput by always create thread when there is a new task. The Executors.newCachedThreadPool is using this queue, and others like newFixedThreadPool and newSingleThreadExecutor are using LinkedBlockingQueue. Here is detail: https://juejin.cn/post/6961815903759499295
DelayQueue
An unbounded blocking queue of Delayed elements, in which an element can only be taken when its delay has expired. The head of the queue is that Delayed element whose delay expired furthest in the past. If no delay has expired there is no head and poll will return null. Expiration occurs when an element’s getDelay(TimeUnit.NANOSECONDS) method returns a value less than or equal to zero. Even though unexpired elements cannot be removed using take or poll, they are otherwise treated as normal elements. For example, the size method returns the count of both expired and unexpired elements. This queue does not permit null elements.
It’s using PriorityQueue for data storage, and using ReentrantLock for thread synchronization, the element need to implmenet Delayed interface which has getDelay() and compareTo() function. The queue has been used in Executors.newScheduledThreadPool function.
Because it’s using PriorityQueue for storage, so every operation’s TC is the same, the only difference is the reentrant lock.
https://blog.csdn.net/fuzhongmin05/article/details/105716205
LinkedBlockingQueue
An optionally-bounded blocking queue based on linked nodes. very like ArrayBlockingQueue, but it’s unbounded by default(bounded by Integer.MAX_VALUE), every element requires a new object so it’s taking more memory, and it’s using 2 locks for consumer and producer, however, ArrayBlockingQueue is using same lock with 2 conditions, so it’s more efficient.
Because it’s a linked list with lock, so its basic operations are O(1) complexity and remove is O(N);
Map
HashMap
A very classic data structure, hashing object to array index, and each node can become a linked list and grow to RBTree while it’s greater than 7. The initial size is 11, and loadFactor is 0.75f. Each time grow *2 and it will have to re-hashing.
All basical operations get(), containsKey(), and put() has O(1) TC.
HashTable
Same as HashMap but has synchronized in each public function, so it’s thread-safe, and TC for all operations are the same.
LinkedHashMap
A HashMap but each entry is a double-head node. so each time when the element is updated, it will not only update the array bucket, but also manipulate the 2 pointers of the node. However, the TC is still same as HashMap.
https://www.jianshu.com/p/8f4f58b4b8ab
IdentityHashMap
This class is not a general-purpose Map implementation! While this class implements the Map interface, it intentionally violates Map’s general contract, which mandates the use of the equals method when comparing objects. This class is designed for use only in the rare cases wherein reference-equality semantics are required.
IdentityMap provides constant-time performance for the basic operations (get, put and remove)
WeakHashMap
Hash table based implementation of the Map interface, with weak keys. An entry in a WeakHashMap will automatically be removed when its key is no longer in ordinary use. It’s useful for cache scenarios.
Same as HashMap, WeakMap has O(1) complexity for the basic operations (get, put and remove)
TreeMap
A Red-Black tree based navigableMap implementation. Each basic operation has O(log N) complexity in order to balance tree dynamically.
ConcurrentHashMap
In jdk1.7HashMap synchronized by segment lock, it composes by multi small hash tables, each small table has a segment lock(extend ReentrantLock), so it’s unblocked and has better performance than HashTable. The shortcoming is it provides weak consistency when iterate because it doesn’t have a global lock to lock the whole instance.
After jdk1.8 the segment lock was deprecated and replaced by linked list + array + RBTree, and it’s using synchronized + CAS for thread synchronize, and it has separat lock for each Node, so the concurrency performance is better than it in jdk1.7.
The operations TC is same as HashTable O(1)
https://www.jianshu.com/p/31f773086e98
ConcurrentSkipListMap
Same as ConcurrentSkipSet, implement by skip list. All basic operations are O(log N) TC.




