 Luke.Du's blog
Luke.Du's blog
Big things, fast, minimal set up, maximum security, low cost.
Foundation
Volume: Amount of data that will be ingested by the solution - the total size of the data coming in.
Velocity: Speed of data entering a solution.
Variety: Number of different sources data come from, and the types of sources.
Veracity: The degree to which data is accurate, precise, and trusted. It;s contingent on the integrity and trustworthiness of the data.
Value: The ability of a solution to extract meaningful information from the data that has been stored and analyzed.
Planning a data analysis solution, you show:
- Know where your data comes from
- Know the options for processing your data
- Know what you need to learn from your data
Volume
Original data storage
AWS S3 Provide object storage capability to store your original data source, you can even build a Data lake base on it.
Structured data storage
- Amazon Redshift - Data Warehouse
- Amazon Redshift Spectrum - Combine Data Lake and Data Warehouse as a single source data
- Data mart - A subnet of a data warehouse
A data warehouse is a central repository of structured data from many data sources. Provide fast, centralized data retrieval. Data in warehouse is transformed, aggregated, and prepared for business reporting and analysis.
A subset of data from a data warehouse is called a data mart. Data marts only focus on one subject or functional area. A warehouse might contain all relevant sources for an enterprise, but a data mart might store only a single department’s sources. Because data marts are generally a copy of data already contained in a data warehouse, they are often fast and simple to implement.
Velocity
Based on different velocity, there are two different way to process data:Batch and Stream.
Batch processing
Batch processing deal with large bursts of data, comes 2 different forms:
- Scheduled: regular, Velocity is very predictable with batch processing. It amounts to large bursts of data transfer at scheduled intervals.
- Periodic: On demand, Velocity is less predictable with periodic processing. The loss of scheduled events can put a strain on systems and must be considered.
Services: Amazon EMR(Hadoop), Apache Spark & Hive
AWS EMR(Hadoop) vs AWS Glue(Spark)
Hadoop is a scalable storage and batch data processing system. It is designed to handle batch processing efficiently whereas Spark is designed to handle real-time data efficiently.
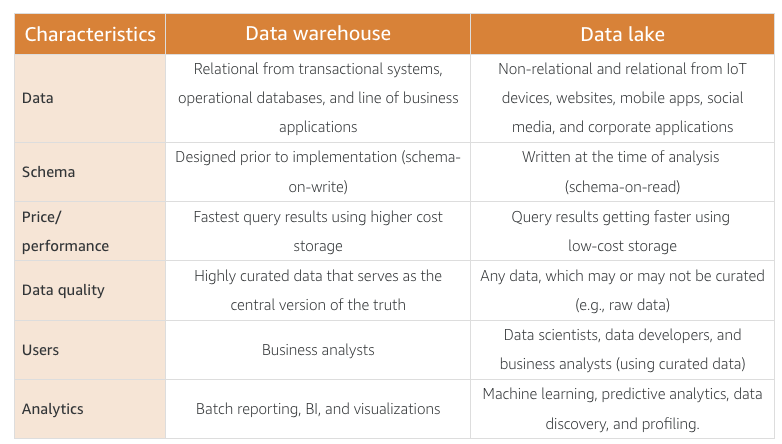
The architecture diagram below depicts the components and the data flow of a basic batch analytics system using a traditional approach. This approach uses Amazon S3 for storing data, AWS Lambda for intermediate file-level ETL, Amazon EMR for aggregated ETL (heavy lifting, consolidated transformation, and loading engine), and Amazon Redshift as the data warehouse hosting data needed for reporting.
Batch data processing with Amazon EMR and Apache Hadoop:
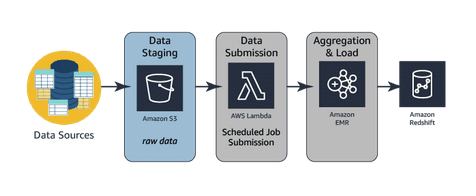
The architecture diagram below depicts the same data flow as above but uses AWS Glue for aggregated ETL (heavy lifting, consolidated transformation, and loading engine). AWS Glue is a fully managed service, as opposed to Amazon EMR, which requires management and configuration of all of the components within the service.
Glue: More managed solution, easy to config:
Stream processing
Stream processing deal with tiny Bursts of data, also comes 2 different forms:
- Real-time: milliseconds: Velocity is the paramount concern for real-time processing systems. Information cannot take minutes to process. It must be processed in seconds to be valid and maintain its usefulness.
- Near real-time: Velocity is a huge concern with near real-time processing. These systems require data to be processed within minutes of the initial collection of the data. This can put tremendous strain on the processing and analytics systems involved.
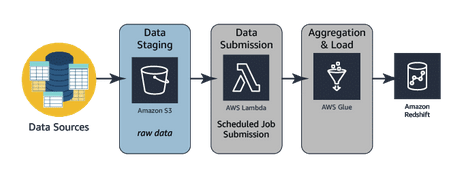
Services: Amazon Knesis Data Firehose, Amazon Kinesis Data Streams, Amazon Kinesis Data Analytics
Stream processing:
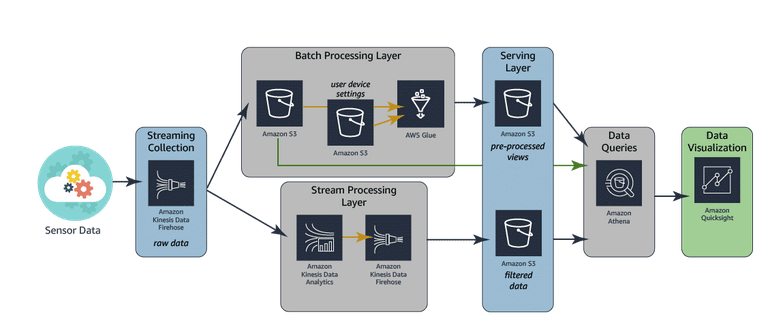
Stream processing & Batch processing:
Variety
Based on different variety, data comes with 3 different structure:
- Structured data: Stored in a tabular format, relational data model, defines and standardizes data element. Limited flexibility
- Semistructured data: Stored as elements and attributes, NOSQL or non-relational database, No pre-defined schema, Can be stored in files, Highly flexible.
- UnStructure data: Stored as files, No pre-defined schema, PDFs and CSV files. Must pre-process all files. Use a service to add tags. Catalog the data.
Structured data is hot, immediately ready to be analyzed. Semistructured data is lukewarm—some data will be ready to go and other data may need to be cleansed or preprocessed. Unstructured data is the frozen ocean—full of exactly what you need but separated by all kinds of stuff you don’t need.
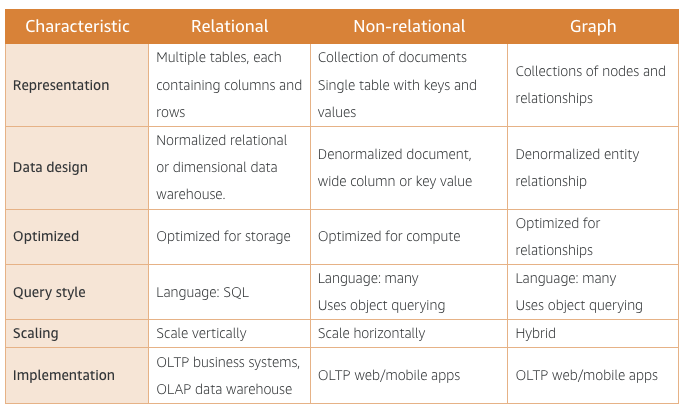
Structured data - Relational databases
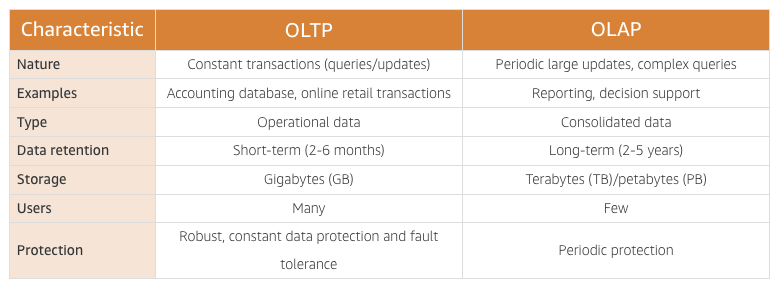
OLTP databases (operational databases) - RDS
Online transaction processing (OLTP) databases, often called operational databases, logically organize data into tables with the primary focus being on the speed of data entry. These databases are characterized by a large number of insert, update, and delete operations.
OLAP databases (data warehouses) - Redshift
Online analytical processing (OLAP) databases, often called data warehouses, logically organize data into tables with the primary focus being the speed of data retrieval through queries. These databases are characterized by a relatively low number of write operations and the lack of update and delete operations.
Non-relational databases - DynamoDB
- Document stores: JSON, BSON, XML
- Key-value store: Single table with specific key
Graph databases - Amazon Neptune
Veracity
Practice to identify data integrity issues:
- Know what clean looks like.
- Know where the errors are coming from.
- Know what acceptable changes look like.
- Know if the original data has value.
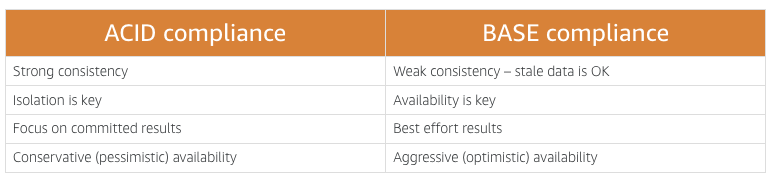
Data consistency - ACID
ACID is an acronym for Atomicity, Consistency, Isolation, and Durability. It is a method for maintaining consistency and integrity in a structured database.
- Atomicity: When executing a transaction in a database, atomicity ensures that your transactions either completely succeed or completely fail. No one statement can succeed without the others. Because many requests to a database are multi-faceted, this interaction is very important for avoiding faults in your data set.
- Consistency: Consistency ensures that all transactions provide valid data to the database. This data must adhere to all defined rules and constraints. For a transaction to complete successfully, all of the statements within it must be valid against all relevant constraints set in the database. If any single statement violates these checks, the whole transaction will be rolled back, and the database will be returned to its previous state. Consistency also ensures that data updates are not made available until all replicates have been updated as well.
- Isolation: Isolation ensures that one transaction cannot interfere with another concurrent transaction. Databases are busy places. Isolation ensures that when multiple transactions request the same data, there are rules in place ensuring that the operations will not cause data corruption and that all data will be made available in an orderly fashion.
- Durability: Data durability is all about making sure your changes actually stick. Once a transaction has successfully completed, durability ensures that the result of the transaction is permanent even in the event of a system failure. This means that all completed transactions that result in a new record or update to an existing record will be written to disk and not left in memory.
Integrity in non-relational database - BASE compliance
BASE is an acronym for Basically Available Soft state Eventually consistent. It is a method for maintaining consistency and integrity in a structured or semistructured database.
- Basically Available: BA allows for one instance to receive a change request and make that change available immediately. The system will always guarantee a response for every request. However, it is possible that the response may be a failure or stale data, if the change has not been replicated to all nodes. In an ACID system, the change would not become available until all instances were consistent. Consistency in a BASE model is traded for availability.
- Soft state: Also known as a changeable state, there are allowances for partial consistency across distributed instances.
- Eventual consistency: This reinforces the other letters in the acronym. The data will be eventually consistent. In other words, a change will eventually be made to every copy. However, the data will be available in whatever state it is during propagation of the change.
ETL
Extracting data
- Where all source data resides.
- When the extraction will take place due to the potential impact of the copy process on the source system
- Where the data will be stored during processing
- How often the extraction must be repeated.
Transforming data
- Change type & structure
- Applying business rules
Loading data
location to load the newly transformed data.
Amazon EMR vs AWS Glue
Amazon EMR is a more hands-on approach to creating your data pipeline. This service provides a robust data collection and processing platform. Using this service requires you to have strong technical knowledge and know-how on your team. The upside of this is that you can create a more customized pipeline to fit your business needs. Additionally, your infrastructure costs may be lower than running the same workload on AWS Glue.
AWS Glue is a serverless, managed ETL tool that provides a much more streamlined experience than Amazon EMR. This makes the service great for simple ETL tasks, but you will not have as much flexibility as with Amazon EMR. You can also use AWS Glue as a metastore for your final transformed data by using the AWS Glue Data Catalog. This catalog is a drop-in replacement for a Hive metastore.
Value
Dashboard: QuickSight
In a big picture
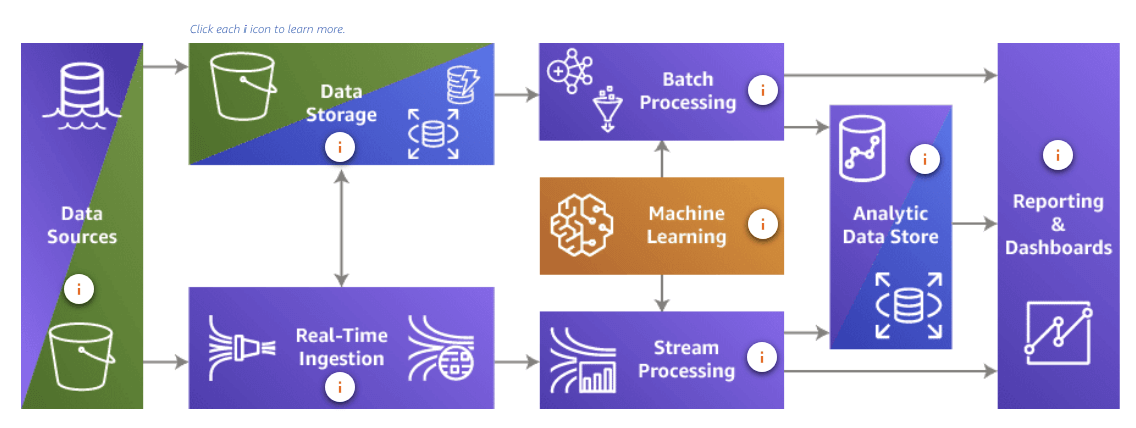
- Data Sources: S3, Data lake build on S3
- Data storage:
- Catalog: Glue
- Database: RDS, Redshift, DynamoDB
- Real-Time ingestion: Kinesis Data Stream, Kinesis Data Firehose
- Batch processing: Amazon EMR, AWS Glue
- ML: ML service
- Stream processing: Kinesis, EC2, Amazon EMR
- Analytic Data Store: RDS, Redshift
- Reporting and dashboards: QuickSight, Amazon ElasticSearch Service, Kibana




