 Luke.Du's blog
Luke.Du's blog
Our team recently had a performance issue with some data processing. Every day we have 24 files of 30GB generated in S3, and we’re having a Fargate cluster to download and process those data, it takes 12 hours to processing all 600+GB files, which is too slow as we want to increase the size of file for processing. After a serial of improvement, we successfully reduce the processing to 1.5 hours.
This is a sample project to explain what improvement we’ve done: https://github.com/ADU-21/s3-parallel-download
Network IO?
We firstly thought about IO would be the bottleneck, in our case the download rely on the network and could be quite time consuming. By looking at the monitor, the download speed is lower than 20MB/s however the bandwidth is 1000 mbps. Obviously for some reason our bandwidth is not fully used.
Single thread to multi threads
The origin way used in our code to download object from S3 bucket is:
1 | awsS3Client.getObject(new GetObjectRequest(buektName, key), new File()); |
It is the most common way to get the object, However it’s single thread solution which is suitable for small object downloading. For large downloads, There is a package named TransferManager as this AWS blog suggesd which is developed to support parallelizing large downloads.
1 | // Initialize TransferManager. |
After using this solution, the download speed the time has been increased from 20MB/s to 100MB/s, in my sample, the download time for a 175MB file decrease from 236,947ms to 41,389ms.
Disk to memory
Sweet win! let’s merge this change to mainline.
This solution working perfectly in local and even non-prod environment, but when it’s pushed to prod, the download speed decrease to 4MB/s.
The only different between non-prod and prod environment is the file size in non-prod is 2GB but prod is 30GB.
We used async-profiler to generate a flame graph, it is appear that almost all CPU is spending on disk file writing:
1 | jps # Show JVM processes |

The reason is when TransferManager download large file, it breaks the file into near 2000 peaces and generate great pressure on disk writing, especially when EFS is used in our case(a similar issue). Becase the limitation was cause by disk IO so we decide to take disk down, and replace file by stream. Unfortunately TransferManager doesn’t support downloading to streams yet, so we have to implement it by ourselves.
The basic idea is break down each file to multi chunks, using a thread pool to parallel download them them and merge together. Because a single file was too big(30GB), it might cause OOM, so there is a parallel processing in the download thread which handles majority data in the chunk. the rest of data (head and tail) store in a stringBuffer with index. In the end, merge the stringBuffers into single string and process them. Belows show a generally idea about the code logic, The complete code can be found here
1 | List<GetObjectRequest> getPartRequests = prepareGetPartRequests(bucketName, key, s3Client); |
After implement this change, the download speed increased from 4MB/s to 65MB/s in prod, in my sample, the download time for 175MB file becomes 86,788ms
TLS decription so slow
Although the speed has increased 3 times, it’s still not enough.
So we used intellij profiler to analysis the CPU costing again:
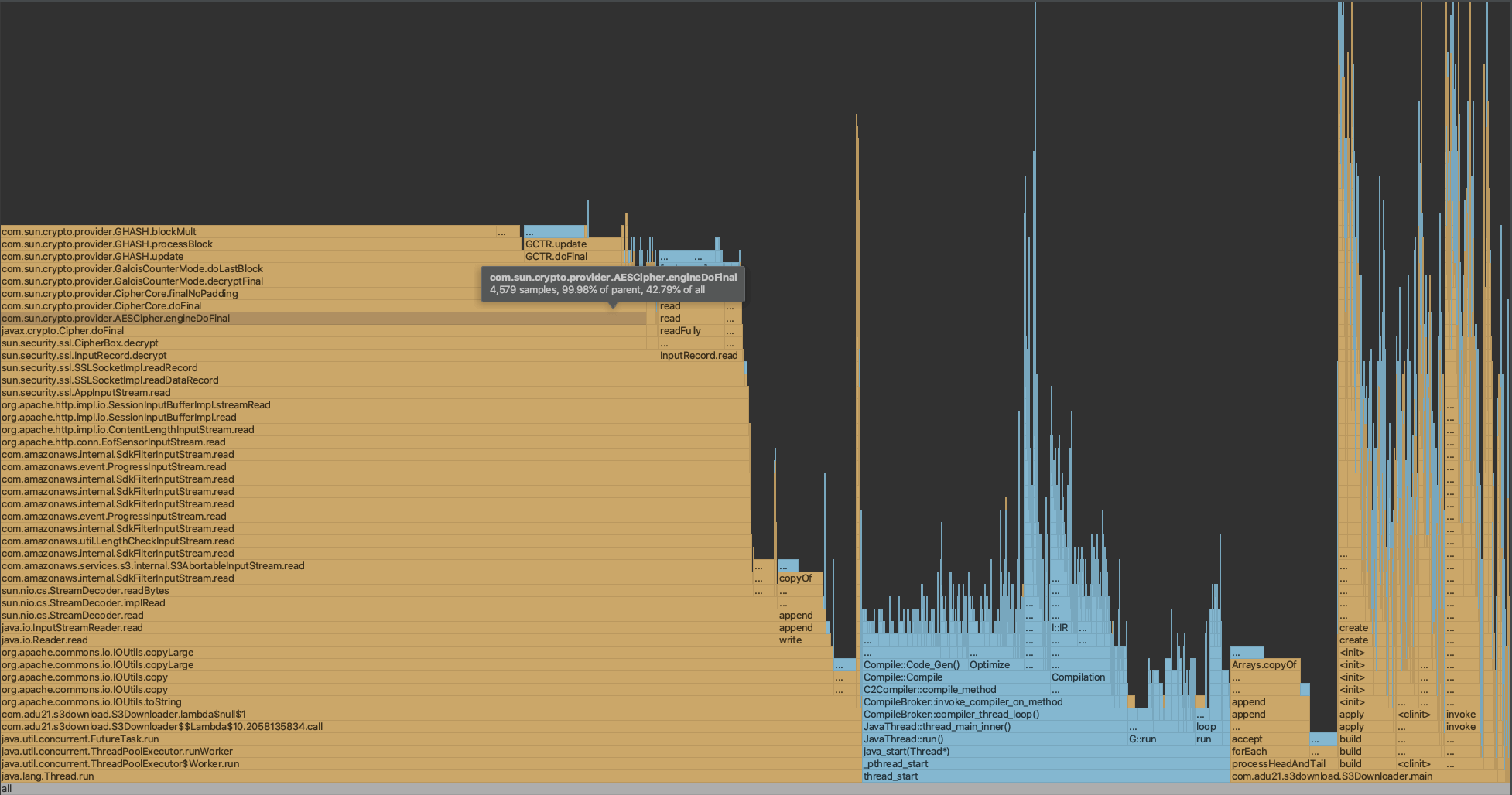
As the graph shown, half of time as spent on AESCipher class which is part of SSL decription. The AESCipher is already highly optimized in JVM since there is hardware CPU instruction to processing.
After discuss with the team, we decide to remove HTTPS and use HTTP instead, because our services are running in a private subnet inside a VPC.
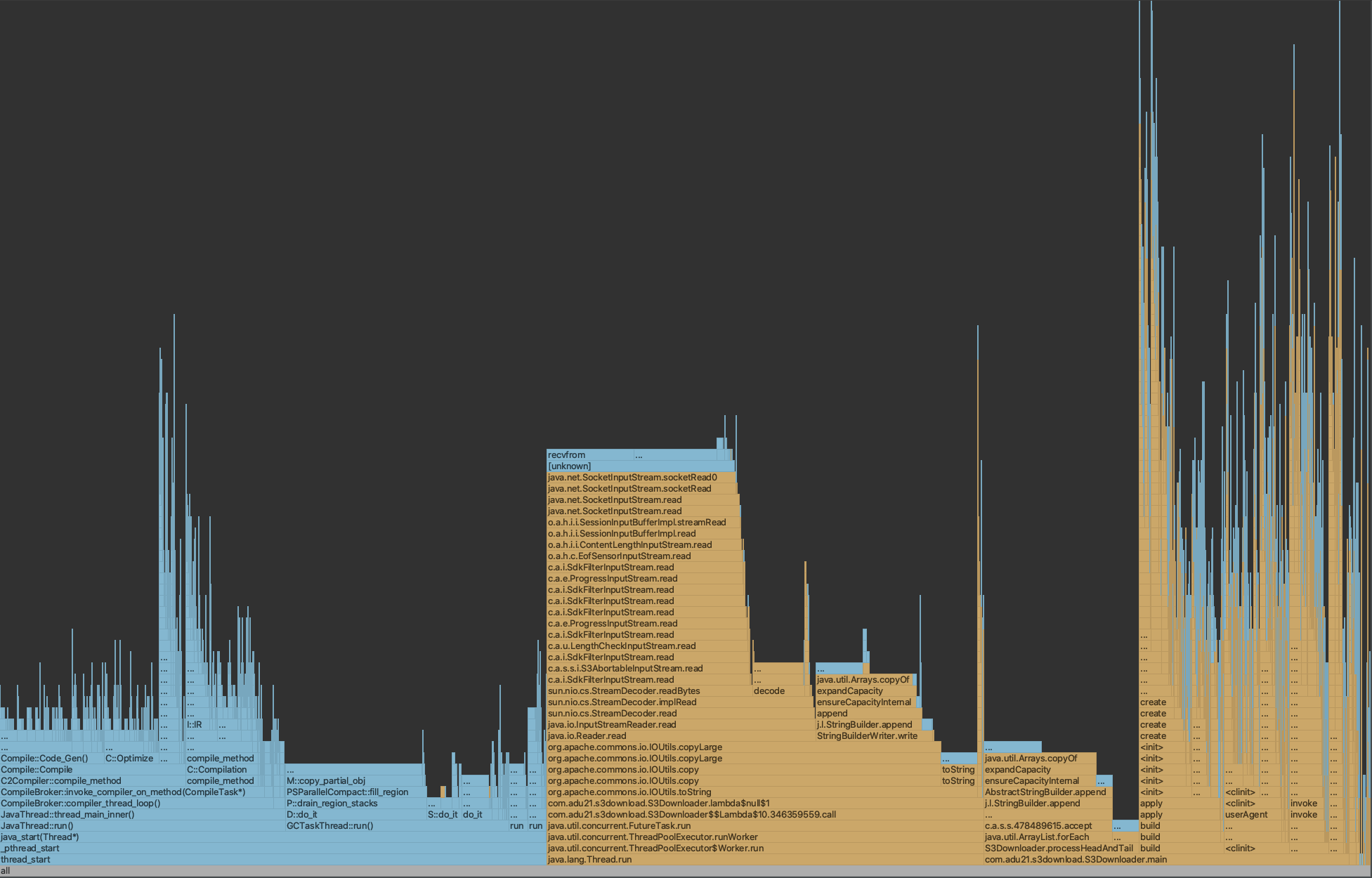
After remove HTTPS, the download spead increased from 65MB/s to 100MB/s, in my sample, the download time for 175MB file decreased from 86,788ms to 61,448ms, the flame graph shows:
Upgrade JDK from 8 to 11
Can we go further? The answer is yes.
Comparing JDK8 and JDK11, we found out JDK11 provided better performance: The GCTaskThread has disappeared which means more CPU power can be used in the business logic:
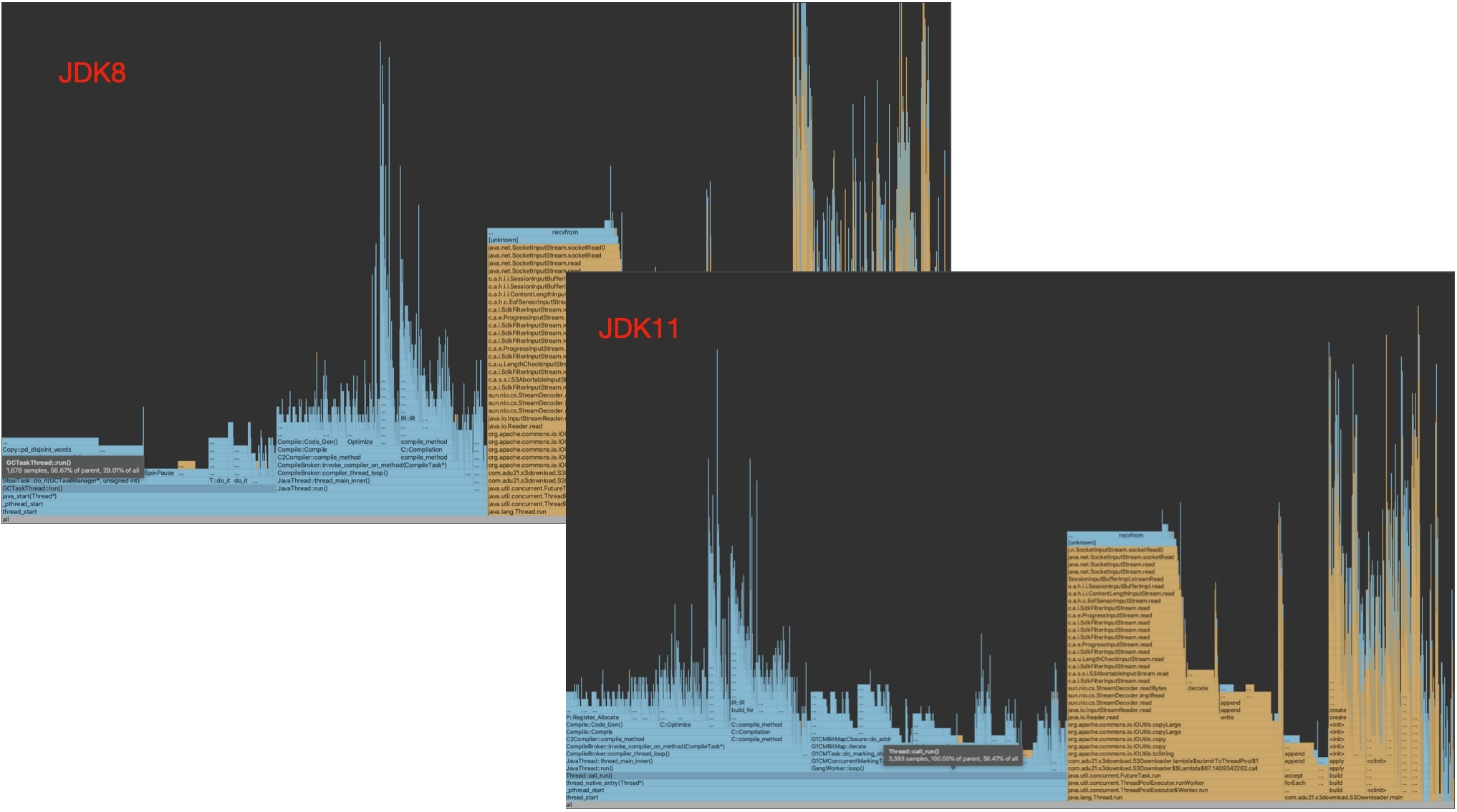
Then we increased number of thread from 5 to 20, the prod download speed increased from 100MB/s to 150MB/s. in my sample, the download time for 175MB file decreased from 61,448ms to 33,481ms.
Summary
In my example, the download spead has been increased by 7 times.
async profiler is a good tool for CPU profiling.




