 Luke.Du's blog
Luke.Du's blog
In order to improve CPU utilization, and more effectively manage jobs in a multiprogramming system, the operation system(OS) abstracts the “process”. Each process has a Process Control Block(PCB*) which contains all information that OS required to manage the process, and resources in user space memory, they’re generally independent of each other, but the kernel space is shared, so communication between processes must go through the kernel.
PCB is composed of PID, State(New, Ready, Running, Wait, Terminated, Suspended ready, Suspended Blocked), Program counter which contains the address of the next instruction to be executed, CPU Registers store in the state information when interruptions occur, CPU-scheduling information like priority and other parameters, Memory-Management information like address of page and segment tables, Accounting information like CPU time used, I/O status information like list of I/O devices allocated to the process, a list of open files, and so on.
In process allocated memory, it has Stack(temporary variables), Data section(global variables), Heap, etc.
Pipe
If you ever used Linux, you must have used | :
1 | netstat -nltp | grep java |
The netstat and grep commands are run in 2 processes, the | between them is a pipe, it passes the output from the previous process into the input of the next process. The data can only flow in one direction and only be used between related processes(they’re either parent-child or children from the same parent process). This is a half-duplex method, in order to achieve a full-duplex, another pipe is needed.
Pip was created using the pipe system call and returns pair of file descriptor(fd), the child inherits the fd table when fork, and each inherited fd refer to the write/read ends of the same open file as in the parent process, which is maintained by the kernel. The parent process will close fd[0] and write into the pipe, and the child process will close fd[1] and read from the pipe, that’s one-way communication.
FIFO
The pipe does not have a name, so we call it anonymous pipe, correspondingly, there is a named pipe, called FIFO. It supports communication between two unrelated processes. It is a full-duplex method.
We can create named pipe via mkfifo:
1 | $ mkfifo myPipe # Create pipe |
Although a pipe can be accessed like an ordinary file, the system actually manages it as a FIFO queue. The essence of a pipe is a buffer in the kernel. Processes access data from the buffer in a first-in, first-out manner. One process writes data to the buffer sequentially, and another process reads data sequentially.
The buffer can be regarded as a circular queue. The reading and writing positions are automatically increased. A piece of data can only be read once, and it will no longer exist in the buffer after it is read.
When the buffer is empty or full, there are certain rules to control the corresponding reading process or writing process to enter the waiting queue. When new data is written in the empty buffer or data is read in the full buffer, the waiting queue is woken up. Processes in continuing reading and writing.
There are limitations for pipe:
- The buffer size has limitations, normally quite small(4096 by default)
- The pipeline transmits unformatted byte stream, which requires the reader and writer to agree on the format of the data in advance
The pipe is an inefficient communication way, it’s not suitable for frequently exchanging data between processes.
Message Queue
A message queue is a linked list of messages stored within the kernel. It is identified by a message queue identifier. This method offers asynchronous communication between single or multiple processes with full-duplex capacity.
1 |
|
There are a few differences between message and pipe:
- Messages don’t have to be fetched in a FIFO order, instead, we can fetch messages based on their type field.
- Unlike pipe transmits unformatted byte stream, each message is a data block that has a fixed size. Producers and consumers need to agree on data type in advance.
- The life cycle of the message queue follows the kernel, the message queue will always exist until specifically delete or OS shut down. However, the anonymous pipe was destroyed at the end of the process.
There are some shortcomings of the message queue:
- Good for asynchronous communication but not for real-time.
- Message has size limitation(8192 by default), not suitable for large-size data transfer.
- In the process of message queue communication, there is data copy overhead between user mode and kernel mode.
Shared Memory
Shared memory solved problems with pipes, FIFO, and message queues that information has to go through the kernel. The shared memory is created by one process but can be accessed by multiple processes, the same physical memory address has been mapped to different visual addresses in different processes, and each process can directly read/write from the memory, it’s the fastest type of IPC because processes access memory directly.
1 |
|
Since multiple processes share a piece of memory, it is necessary to rely on some synchronization mechanism (such as semaphore) to achieve synchronization and mutual exclusion between processes.
Semaphore
A semaphore is simply an integer variable that is shared between processes. This variable is used to solve the critical section problem and to achieve process synchronization in the multiprocessing environment.
Semaphores are of two types:
- Binary Semaphore
This is also known asmutex lock. It can have only two values – 0 and 1. Its value is initialized to 1. It is used to implement the solution of critical section problems with multiple processes. - Counting Semaphore
Its value can range over an unrestricted domain. It is used to control access to a resource that has multiple instances.
1 |
|
There are two atomic operations for controlling the semaphore: P, V
P subtracts 1 from the semaphore. After subtraction, if the semaphore < 0, it indicates that the resource is occupied and the process needs to block and wait; if the semaphore >= 0, it indicates the resource is available, and the process can continue executing.
V will add 1 to the semaphore. After the addition, if the semaphore <= 0, it means that there is currently a blocked process, so the process will wake up and run; if the semaphore> 0, it means that there is currently no blocking process;
The P operation is used before entering the shared resource, and the V operation is used after leaving the shared resource. These two operations must appear in pairs.
Signal
The inter-process communication mentioned above is the working mode in the normal state. when an error happens, it is necessary to use “signal” to notify the process.
The command used to send signal is kill, we can use kill -l to see all signals we can send:
1 | $ kill -l |
There are a few common scenarios for using signals:
Ctrl + C=SIGINT, it means terminate the processCtrl + Z=SIGTSTP, it means stop the process, but not terminate.kill -9 <PID>=SIGKILLkill the process immediately
The signal is an asynchronous communication mechanism, a signal can be sent to a process at any time. Once a signal is generated, the process can decide either to execute the default operation, customize the operation, or ignore the signal, there are 2 signals that can not be ignored, SIGKILL and SIGSTOP.
Socket
The socket is normally used for network communication, but it can also be used to communicate 2 processes in the same host.
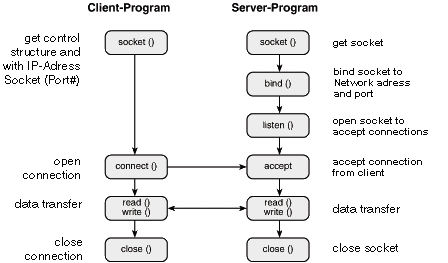
1 | // Server side |
The biggest difference between local socket and TCP/UDP is, TCP and UDP bind IP address and port, but local socket bind a local file.
What about Thread?
After knowing 7 different ways to communicate through processes, now let’s look at threads.
Thread is also known as lightweight process, a thread contains Thread Id, A Program counter, A register set, A stack, and shared code section, data section, and other os resources, such as open files and signals with other threads in the same process.
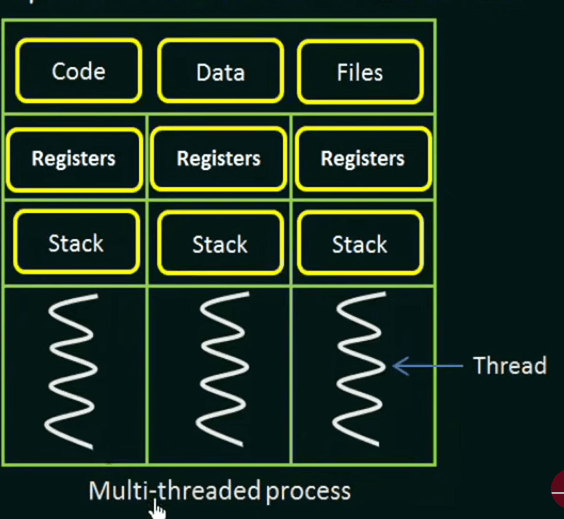
Unlike processes, threads share the same memory space within a single process, so any shared variable can be used to communicate, like global variables.
There are 2 types of threads: User Level thread(ULT) and Kernel Level thread(KLT). ULT is implemented in the user-level library, they are not created using the system calls. Thread switching does not need to call OS and cause interruptions to Kernel. The kernel doesn’t know about the user-level thread and manages them as if they were single-threaded processes. It can be implemented on an OS that doesn’t support multithreading.
Coroutine
Coroutine(Cooperative-Routine) is even lighter than ULT, also known as fiber or Green Thread, a running coroutine must explicitly “yield” to allow another coroutine to run, which makes their implementation much easier.
A coroutine has its own register context and stack*, when a coroutine scheduler switches, register context, and stack are saved to another place. In coroutines, the operating stack basically does not have kernel switching overhead hence context switching is faster, and because it converts asynchronous to synchronous, it can access global variables without a lock.
Coroutines can be stackless: they suspend execution by returning to the caller and the data(register status) that is required to resume execution is stored separately from the stack. This mechanism avoids the traditional function call stack, theoretically, it can achieve infinite recursion, and because coroutines do not have context switching in kernel mode, and can be concurrency infinitely.
Parameters can be shared across coroutine by global shared variables, channel communication, and register context, different language have different implementations.
The major difference between coroutine and thread is that coroutines are cooperative, threads are preemptive.
Summarize
Pipe and Signal are easy to use as user interfaces, the message is widely used in asynchronous scenarios, and shared memory is the most effective way, especially for large data share but needs to cooperate with semaphore as resources locker.
Reference
- https://www.baeldung.com/cs/process-control-block
- https://www.nginx.com/blog/what-are-namespaces-cgroups-how-do-they-work
- https://www.guru99.com/inter-process-communication-ipc.html
- https://man7.org/linux/man-pages/man7/pipe.7.html
- https://unix.stackexchange.com/questions/11946/how-big-is-the-pipe-buffer
- https://learnku.com/articles/44477
- https://www.cnblogs.com/xiaolincoding/p/13402297.html
- https://en.wikipedia.org/wiki/Coroutine
- https://cloud.tencent.com/developer/article/1797459




