 Luke.Du's blog
Luke.Du's blog
Apache Kafka Study Note
Apache Kafka is an open source distributed event store and stream-processing platform. Since 2012, it has gained increasing popularity among users due to its excellent performance and flexible configuration. Today, more than 80% of all Fortune 100 companies is using Kafka.
Read more

Distributed Cache in Practice
Caching is a crucial technique used in modern computing to improve system performance and reduce latency. It involves storing frequently accessed data closer to the users, reducing the need to retrieve the same data repeatedly from the original source.
Read more
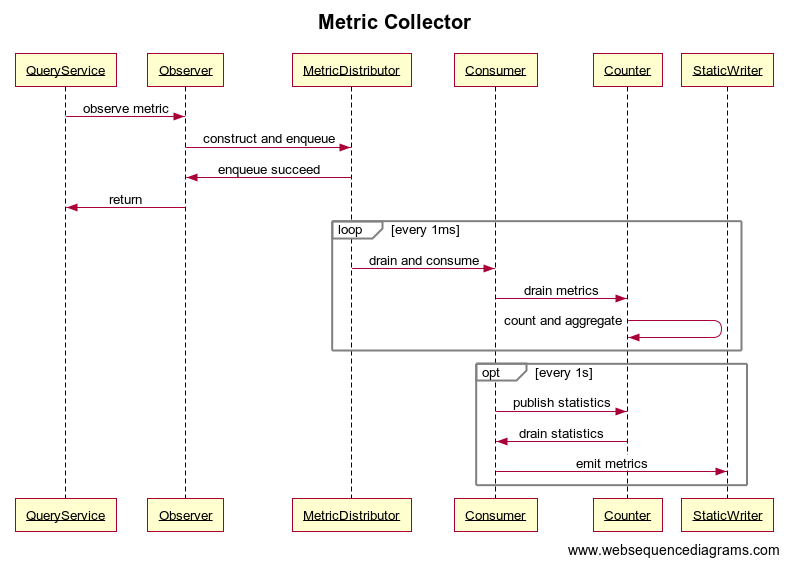
Producer-Consumer Pattern with Non-Blocking Queue
Metrics are vital for the distribution system, this article describes how to implement a metric function for a high TPS system.
The code can be found here: https://github.com/ADU-21/producer-consumer
Read more

Throttling in Distributed System
Throttling is one of the three effective methods for protecting a high concurrency system. The other two are respectively caching and downgrading. Throttling is used in many scenarios to limit the concurrency and the number of requests. Our service has tens of millions of TPS, with tens of thousands of hosts serving traffic. Throttling is vital for such a large distributed service.
Read more

Working expeirence at Alibaba vs Amazon as engineer
Util today I’ve been working at Amazon for 1 year and 9 months, almost same as I have been working at Alibaba, I was lucky enough to go through the full project cycle at both companies as an engineer, I’ll describe the the fact and thoughs based on my expeirence and comparing those 2 companies.
Read more


Speed Up Your AWS S3 Client
- AWS, Java, S3, Performance
Our team recently had a performance issue with some data processing. Every day we have 24 files of 30GB generated in S3, and we’re having a Fargate cluster to download and process those data, it takes 12 hours to processing all 600+GB files, which is too slow as we want to increase the size of file for processing. After a serial of improvement, we successfully reduce the processing to 1.5 hours.
This is a sample project to explain what improvement we’ve done: https://github.com/ADU-21/s3-parallel-download
Read more

AWS DynamoDB Study Note
DynamoDB was announced by Amazon CTO Werner Vogels on in 2012, 14 years after NoSQL was proposed in 1998. It supports key-value and document-oriented structure storage.
Read more
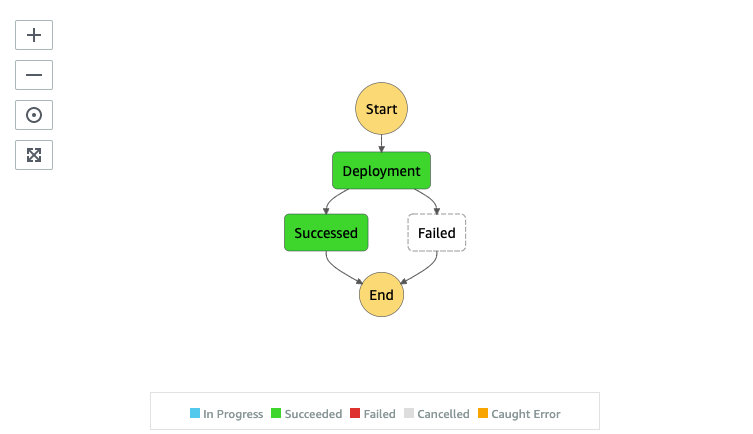
AWS Step Function
Our client recently has a deployment system that has been in use for more than 10 years and wants to migrate to the cloud, this blog shows how we migrate it step by step from a huge single application to serverless by AWS Step funtion.
Read more
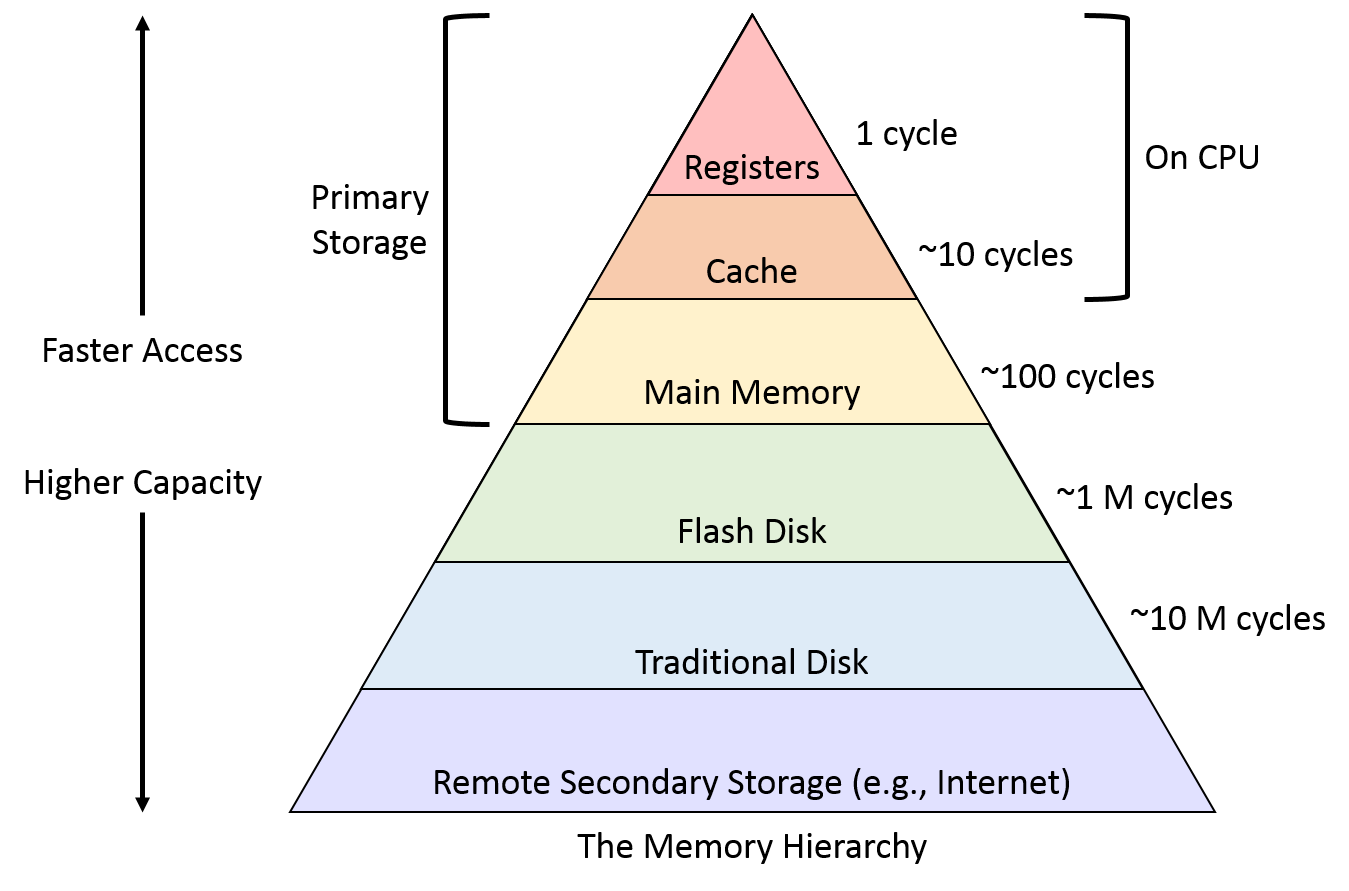
OS Memory Management
In Computer Systems, the CPU is much faster than the storage system, so ideally we want storage system read/write as fast as possible, unfortunately, the price of storage media increases exponentially with the access speed. Thus, in order to balance cost and performance, we designed a multi-layer memory hierarchy.
Read more