 Luke.Du's blog
Luke.Du's blog
Apache Kafka is an open source distributed event store and stream-processing platform. Since 2012, it has gained increasing popularity among users due to its excellent performance and flexible configuration. Today, more than 80% of all Fortune 100 companies is using Kafka.
Key Concept
- Topic: A topic in a Kafka cluster, similar as queue concept in SQS, can have multi producers and consumers
- Record: Also called event, or message
- Cluster: A set of Linux servers running Kafka nodes, a simple cluster normally compose by 3 nodes
- Broker: A host in the Kafka cluster
- Partition: One topic can be divided into multi partitions. Each partition can be store in different broker, each partition has leader and follower, the follower partition is the replica of the leader
- Leader-Follower: The Primary partition and the replicas
- ISR(In Sync Replica): All the replicas of a partition that are “in-sync” with the leader
- Segment: Each partition is separated into segments. Each segment is stored in a single data file on the disk. By default, each segment contains either 1 GB of data or a week of data
- Offset: A position within a partition for the next message to be sent, all records behind this pointer were considered deleted
- Offset Index: An offset to position index, helps Kafka know what part of a segment to read to find a message.
- Timestamp Index: A timestamp to offset index, allows Kafka to find messages with a specific timestamp.
- log: The sequential store include all records in the segment
Kafka Architecture
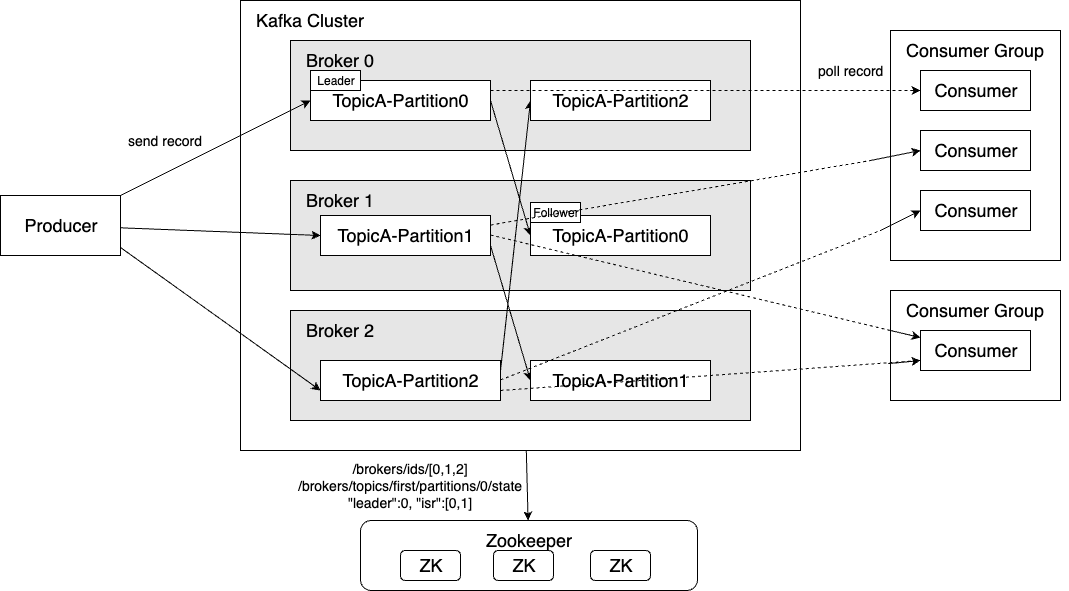
- Producer can send records to any partition, any broker can redirect send request to the broker with leader partition.
- Follower partition from another broker poll the records from leader for replication.
- Each consumer within a group consuming data from different partitions, a partition can only be consumed by one consumer within the group. However, consumers from different groups can consume same partition.
- Brokers poll cluster information from Zookeeper, include broker health information, each partitions’ leader and ISR. this component was in deprecate path and will be replace by Craft after Kafka4.0.
SendMessage
Kafka producer supports sync and async send, for sync producer it provides ACK(0, 1, -1) to decide whether to succeed a request when producer sends succeed, or leader response succeed, or all followers response succeed. Kafka also provide idempotence and transaction to guarantee exactly one delivery. The data flow for an aync send with ACK=-1(All) is like:

- Producer get calculate partition info
- Producer batch records to accumulator
- Sender drain records from accumulator and send to Leader partition
- Leader partition sync to replica and confirm record persist succeed
Consumer Subscribption
Before recieve message, consumer need to subscribe topics or assign partitions, through coordinator, the high level process is:
- The consumer send
FindCoordinator(groupId)to any Broker, and response coordinator endpoint. - Consumer send
JoinGroup(subscription)request to coordinator and get memberId in response. - Consumer send
SyncGroup(memberId)request and get assignment in response - Consumer can now start poll records, and keep sending
HeartBeatrequest to coordinator every 3s, coordinator will rebalance consumers if any consumer failed heartbeat in 45s.
More information: https://developer.confluent.io/courses/architecture/consumer-group-protocol/
ReceiveMessage
Consumer need to be registered before consume message, different consumers in a group can subscribe to different partitions, one partition can consumed by multi consumer groups. However, each consumer group will have different offset, which means consumers in different groups will consume duplicate message. If customer want to have multi consumer to “shard” a single topic, they have to increase number of partitions corresponding to the number of consumers.
Kafka Consumer supports auto offset, manual commit offset(sync and async), a poll with manual sync commit offset is like:

- Consumer poll records from leader partition
- Records store in completedFetches queue via callback function
- Consumer poll records from the queue
- Consumer process data
- Consumer commit offset to
__connsumer_offsetstopic, this is a system internal topic stores all offsets for each consumer - If any consumer failed heartbeat, coodinator will send rebalance request to all consumers
- Another consumer in same the group assigned same partition fetches offset from
__consumer_offsettopic.
Kafka Storage
Why Kafka Sequential storage so effective? there are 5 reasons we’ll walk through
- Fix size sharding
- Sequential writing
- Sparse index reading
- Immutable
- page cache and zero-copy
Sharding & Sequential Writing
Topic is a logical concept in Kafka storage layer, it was shard as partitions separated in different brokers. Logically, each partition is a sequential store(Log). To shard further, each partition was separated as multi segments, a segment is a folder named<topic>-<partition-id>, it contains index, log, timeindex , snapshot and metadata files. By default, a segment stores up to 1GB or 1 weeks records, each log file is named with the offset of the first record it contains, so the first file created will be0000000000000000.log
All records are appended into the latest log file’s tail(sequential writing), the offset will be updated in corresponds index file.
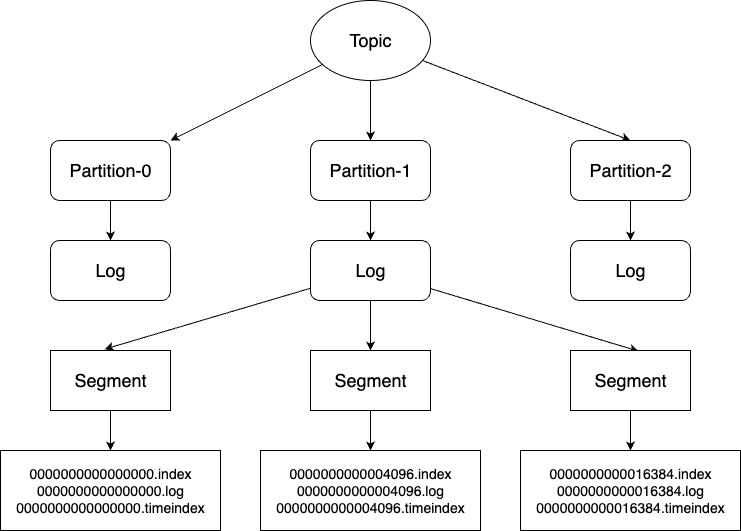
Index
The index file stores relative offset and positions sparsely, by default every 4KB records wrote into log file, the index will add one entry.
For example contents of 000---180.index file were:
1 | offset: 217 position: 4107 |
Contents of 000---180.log file were:
1 | offset: 217 position: 4107 CreateTime: 1537550091903 isvalid: true keysize: 0 valuesize: 43 magic: 2 compresscodec: NONE producerId: -1 sequence: -1 isTransactional: false headerKeys: [] |
By perform binary search on index file, the use position to identify records in log file, Kafka achive high performance reading.
Delete
Instead of delete record one by one, Data is deleted one log segment at a time, the default retention period is 7 days, when the largest timestamp in a segment file was expired, the entire segment file will be deleted.
Cache
Kafka brokers utlize the page cache provide by Linux Kernel for data storage and caching, instead of application level cache, which cacehes frequently accessd data in memory to improve read and write performance.
Next Step
Kafka is quite good at high throughput and event streaming. However, compare to AWS SQS, Kafka doesn’t support inflight state, makes it doesn’t support fanout scenario very well, Kafka has a proposal to support queue liked feature, looking forward to that in the future.
Reference
- https://github.com/apache/kafka
- https://kafka.apache.org/documentation/
- https://docs.confluent.io/kafka/introduction.html
- https://www.conduktor.io/kafka/what-is-apache-kafka/
- https://www.youtube.com/playlist?list=PLmOn9nNkQxJHTVxt3wxWXyheQPLlh-9T6
- https://duyidong-archive.s3.amazonaws.com/pdf/kafka-tutorial.pdf
- https://developer.confluent.io/courses/architecture/get-started/
- https://stackoverflow.com/questions/52338890/kafka-partition-index-file
- https://strimzi.io/blog/2021/12/17/kafka-segment-retention/
- Kafka API models




