 Luke.Du's blog
Luke.Du's blog
CPU Scheduling is a process of determining which process will own CPU for execution while another process is on hold. The main task of CPU scheduling is to make sure that whenever the CPU remains idle, the OS at least selects one of the processes available in the ready queue for execution.
Scheduling Criteria
- CPU utilization: We want to keep the CPU as busy as possible.
- Throughput: Number of processes that are completed per time unit
- Turnaround time: Total time takes to execute a process, from submission to completion. Include waiting to get into memory, waiting in the ready queue, executing on the CPU, and doing I/O
- Waiting time: Amount of time a process has been waiting in the ready queue
- Response time: Time from the submission of a request until the first response is produced, this is the time it takes to start responding, not the time it takes to output the response. The turnaround time is generally limited by the speed of the output device.
Scheduler types
Schedulers are special system software that handles process scheduling in various ways. Their main task is to select the jobs to be submitted into the system and to decide which process to run.
There are three types of Scheduler:
- Long-term (job) scheduler – Selecting the
jobsfrom thebacklog queuein thesecondary memoryand loading them into theready queuein themain memoryfor execution, creating processes, and allocating resources. It makes a decision about how many processes should be made to stay in the ready state based on resources needed fromJCB(Job Control Block)and resources available. This decides thedegree of multiprogramming. - Short-term (CPU) scheduler – Decides which of the process in the
ready queueto be executed (allocated a CPU) after aclock interrupts, anI/O interrupt, anoperating system call, or another form ofsignal. It executes much more frequently than the long-term scheduler as a process may execute only for a few milliseconds. Its main objective is to increase system performance under the chosen set of criteria. - Medium-term scheduler – It is in charge of handling the
swapping outprocess that is moving the process from main memory to secondary and vice versa. The medium-term scheduler may decide to swap out a process that has not been active for some time, or a process that has a low priority / high page faulting frequently / taking up a large amount of memory in order to free up main memory for other processes, it can swapping the process back in later when more memory is available, or when the process has been unblocked and is no longer waiting for a resource.
After the
short-term schedulerselects a process from the ready queue, theDispatcherperforms the task of allocating the selected process to the CPU, and handling context switch, addressing, user/kernel switching after that.
Scheduling Algorithm
- FCFS(First-Come, First-Served): The simplest scheduling algorithm, non-preemptive, low throughput because of long waiting time for long job/process. Good for CPU-bound jobs.
- SJF(Shortest-Process-First): Maximum throughput as waiting time is the shortest. However it’s not good for long jobs, starvation is possible, didn’t consider priority, estimated time is not accurate.
- Priority-Scheduling Algorithm: It can be either preemptive or non-preemptive, preemptive is good for the batch system, and non-preemptive is good for real-time processing.
- Static(Fixed) Priority - Priority is an integer generated when the process was created, based on type, resource, and user demand, it won’t change during run time.
- Dynamic Priority- Priority was initialized when the process was created, and changed during run time. A typical example is Highest Response Ratio Next(HRRN), where
Response Ratio = ( W + S) / S, the W iswaiting time, and S isservice time/burst time. it’s usingagingsolvedSJF‘s starving problem. However, the priority calculation will increase the system cost.
- RR(Round-Robin): The scheduler assigns a fixed time unit per process(time sharding), and cycles through them. Good for the real-time system as it has a good average response time. but it also involves extensive overhead, especially with a small time unit.
- Multilevel Feedback Queue Scheduling(MLFQ): Having multi queues with different priorities, when the process is created it was put into the first priority queue, and processed as
FCFSbyRR, if a process wasn’t able to finish in a unit of time, it will be suspended and put into a lower priority queue, and lower priority queue only execute when higher priority queues are empty.

- Multilevel queue scheduling(MLQ): Very similar to MLFQ, but the queues were categorized as background processes(FCFS) and foreground processes(RR), and processes are assigned permanently into queues, the queues will be executed based on fixed priority.
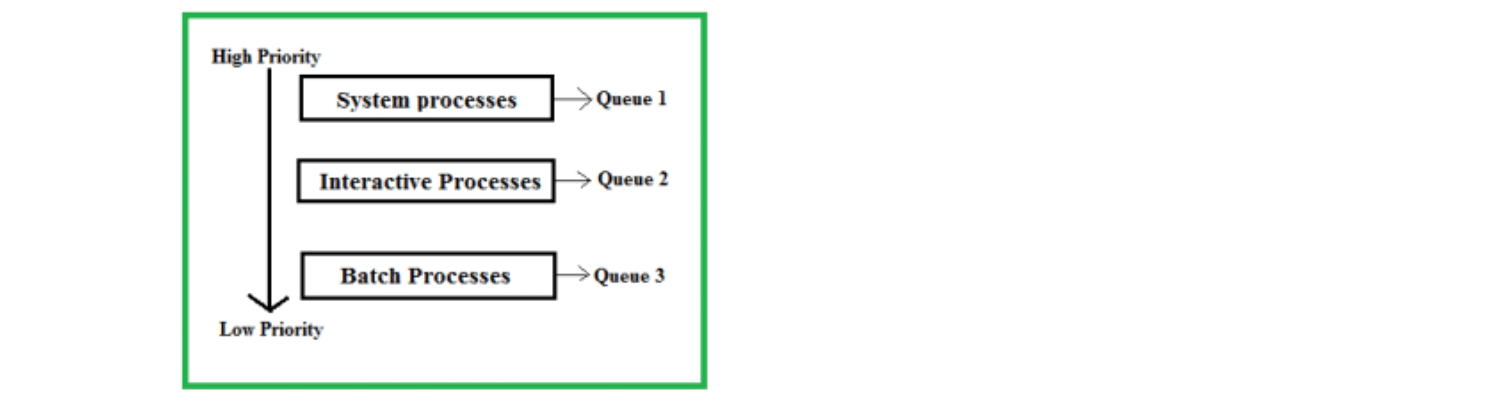
Dynamic priority scheduling algorithm used in real-time operating system.
- Earliest Deadline First(EDF): At every scheduling point the task having the shortest deadline is scheduled for execution. In EDF, priorities to the task are assigned according to the absolute deadline.
- Least Slack Time(LST): At every scheduling point the task having the minimum laxity is executed first. It assigns priorities to processes based on their slack time. Slack time is the amount of time left after a job if the job was started now. This algorithm is also known as least laxity first(LLF).
Deadlock
Deadlock is a situation where a set of processes are blocked because each process is holding a resource and waiting for another resource acquired by some other process.
There are some necessary conditions for deadlocks.
- Mutual exclusion: At least one resource must be held in a non-shareable mode( Only one process can use a resource at any given time)
- Hold and wait: A process waits for some resources while holding another resource at the same time.
- No preemption: A resource cannot be taken from a process unless the process releases the resource.
- Circular wait: A set of processes are waiting for each other in circular form.
Difference between
starvationanddeadlockStarvation is a situation where all the low-priority processes got blocked, and the high-priority processes execute. It’s a long waiting but not an infinite process.
Every deadlock has starvation but starvation doesn’t necessarily have a deadlock.
Prevention
Since deadlock occurs when all the above four conditions are met, we try to prevent any one of them, thus preventing a deadlock.
- Mutual exclusion:
- Make resources sharable(not generally practical)
- Hold and wait:
- Process can not hold one resource when requesting another
- Process requests, release all needed resources at once
- Preemption:
- OS can preempt resource (costly)
- Circular wait:
- Impose an ordering (numbering) on the resources and request them in order(popular implementation technique)
Let’s use the famous Dining philosophers problem as an example, the chopsticks represent resources, and the philosophers represent processes, there are 3 common solutions for this problem:
Avoid hold and wait:
- Resource hierarchy: Order chopsticks by 1 - 5, all philosophers pick up lower-ordered chopsticks first, then pick up higher-ordered one, and release in reversed order.
- Arbitrator solution: Introduce a waiter to guarantee that a philosopher can only pick up both chopsticks or none.
Avoid circular wait:
- Limit process: Limiting the number of diners on the table
- Process hierarchy: Order philosophers by 1 - 5, the odd number takes the left chopstick first, the even number takes the right first, And the release goes reverse order.
Avoidance
is a resource allocation and deadlock avoidance algorithm. The banker knows 4 things:
- How much of each resource the system currently has available(AVAILABLE)
- How much of each resource each process could possibly request (MAX)
- How much of each resource each process is currently holding (ALLOCATED)
- How much of each resource each process still required(NEED)
ALLOCATE + NEED = MAX
When a client(process) requests a resource, it gives a REQUEST, the banker will do:
- If
REQUEST > NEEDwhich means the process is asking more than it should,reject. - if
REQUEST > AVAILABLEwhich means the system doesn’t have enough resources,wait. - Otherwise,
allocatethe resource and perform:AVAILABLE -= REQUEST;ALLOCATION += REQUEST;NEED -= REQUEST;
Detection
Resource Allocation Graph(ARG) can be used to detect locks in system run time, it has 2 types of vertice: resource and process, resource can be either single instance or multiple instance; and 2 types of edges: assign and request.
Here is an example of single instances ARG:
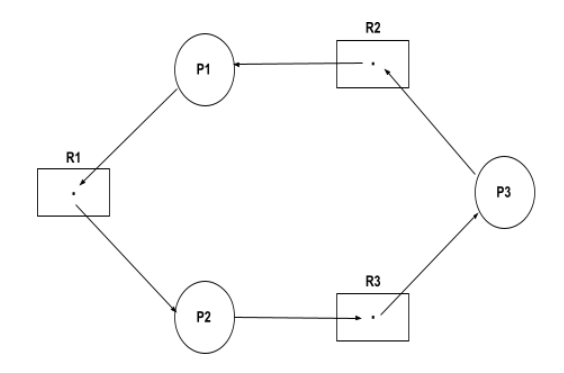
In the above single instances RAG example, it can be seen that P2 is holding the R1 and waiting for R3. P1 is waiting for R1 and holding R2 and, P3 is holding the R3 and waiting for R2. So, it can be concluded that none of the processes will get executed and there will be a deadlock.
Here is another example of multiple instance RAG:
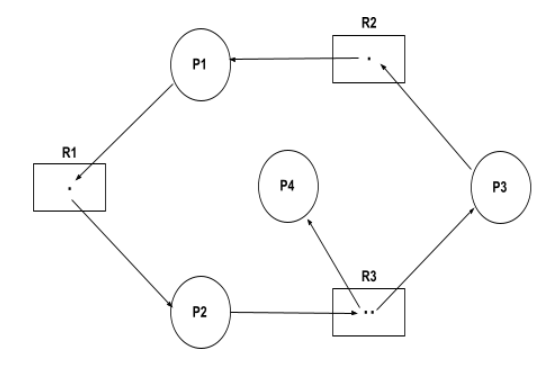
Algorithm to check deadlock
- First, find the currently available instances of each resource.
- Check for each process that can be executed using the
allocated+available resource. - Add the allocated resource of the executable process to the available resources and terminate it.
- Repeat the 2nd and 3rd steps until the execution of each process.
- If at any step, none of the processes can be executed then there is a deadlock in the system.
Using the above algorithm, we will get that there is no deadlock in the above-given example, and their sequence of execution can be P4 → P2 → P1 → P3.
Note: Unlike Singles Instances RAG, a cycle in Multiple Instances RAG does not guarantee that the processes are in deadlock.
Recovery
Once a deadlock is detected, we have 2 options:
- Abort processes
- Abort all deadlocked processes - processes need to start over again
- Abort one process at a time until the cycle is eliminated - the system needs to rerun the detection after each abort.
- Preempt resources (force their release)
- Need to select processes and resources to preempt
- Need to rollback process to the previous state
- Need to prevent starvation
Reference
- https://en.wikipedia.org/wiki/Scheduling_(computing)
- https://developer.aliyun.com/article/897203
- https://www.jianshu.com/p/8f4305d2f0c2
- https://www.prepbytes.com/blog/operating-system/difference-between-mlq-and-mlfq-cpu-scheduling-algorithms/
- https://www.geeksforgeeks.org/difference-between-edf-and-lst-cpu-scheduling-algorithms/
- https://www.geeksforgeeks.org/introduction-of-deadlock-in-operating-system/
- https://colobu.com/2022/02/13/dining-philosophers-problem/
- https://workat.tech/core-cs/tutorial/resource-allocation-graph-rag-os-lz5lltbbl8u7
- https://cseweb.ucsd.edu/classes/fa06/cse120/lectures/120-fa06-l8.pdf




