 Luke.Du's blog
Luke.Du's blog
DynamoDB was announced by Amazon CTO Werner Vogels on in 2012, 14 years after NoSQL was proposed in 1998. It supports key-value and document-oriented structure storage.
Relational Databases is friendly to DDD(Domain Driven Development), provide point in time of the transactions to ensure consistency, however, it can be costly to do horizontal scale(read/write replications) and vertical scale(schema changes). That’s why we some time need NoSQL to save some money in business scenarios that do not require transactions and are not sensitive to consistency.
ACID Vs BASE
If you have experience with relational Database, you must familiar with ACID(atomicity, consistency, isolation, durability), in order to support transaction, NoSQL like DynamoDB is more intend to support BASE model:
- Basic Availability: The database appears to work most of the time.
- Soft state: Stores don’t have to be write-consistent, nor do different replicas have to metually consistent all the time.
- Eventually consistency: Store exhibit consistency at some later point(e.g. lazily at read time)
By adopt BASE model, NoSQL databases sacrificed consistency in exchange for availability, best effort, and faster and easier chema eveolution.
Since consistency is clearly the shortcoming of NoSQL, however consistency can be critical some time for the business (even you didn’t thought about it at first time), AWS has made some improvements to allow users to ensure consistency by sacrificing performance in specific operations. That’s the reason you can see those highlights for DDB:
- Support both key-value and document data models
- Consistent responsiveness
- Single-digital millisecond response
- ACID transaction support
- SLA to 99.999%
- On-demand backups and point-in-time recovery
DynamoDB Basic
Partition key & Sort key
DynamoDB stores data in partitions, A partiction is an allocation of storage of a table, backed by SSDs(Soild-State Drives) and automatically replicated across multiple AZ(Availability Zones) within an AWS region. Imaging DDB is a big HashTable, the partition key is the hashkey to identify where the value going to store, DDB is using an internal hash function to get the item by partition key. That’s why partition key was so important. Sort key is more for filter and ordering purpose.
- The partition key or partition and sort key are used to uniquely write or read an item.
- Partition key is used for partition selection via the DynamoDB internal hash function
- One partition holds 10GB of data an d supports up to 3000 read capacity units(RCU) or 1000 write capacity units(WCU)
- Partition key is used to select the item(s) to read/write
- Sort key is used to range select(e.g. begins_with) or to order results
- Sort key may not be used on their own.
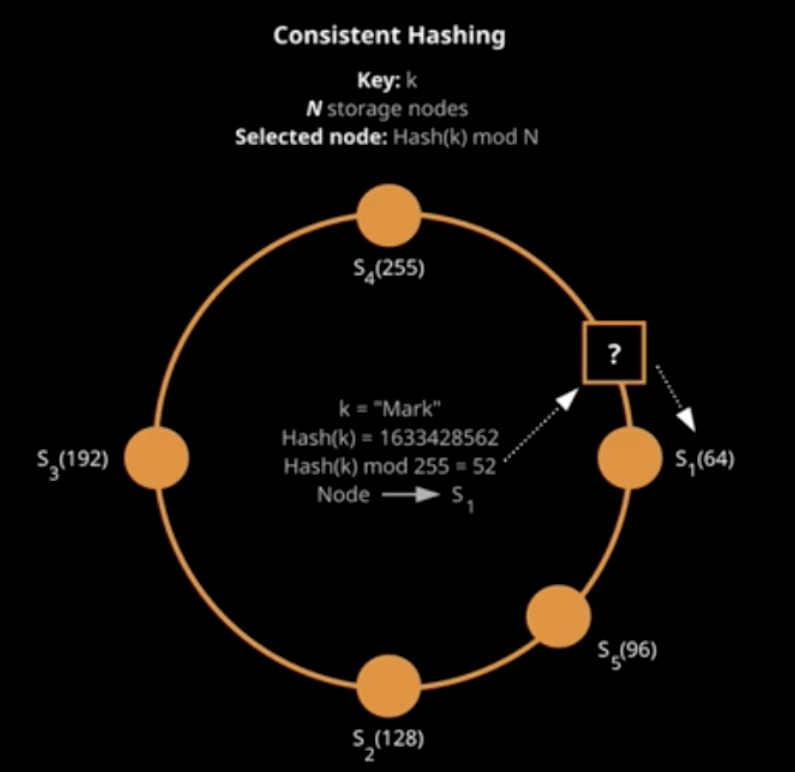
How does DynamoDB determine which storage node get which items
Consistent Hashing: Distribute items evenly on Storage nodes through modulo operation
Read / Write Capacity Unit
There are couple factors need to considered before create new DDB table: like total size and performance.
Read Capacity Units(RCUs)
One RCU represents one strong consistent read request per second, or two eventually consistent read requests, for an item up to 4KB in size. Transactional read requests require 2 RCUs for items up to 4KB.
Filtered query or scan results consume full read capacity.
For an 8KB item size:
- 2 RCUs for one strongly consistent read
- 1 RCU for an eventually consistent read
- 4 RCUs for a transactional read
Write Capacity Units(WCUs)
One WCU represents one write per second for an item up to 1KB in size.
Transactional write requests require 2 WCUs for item up to 1 KB.
For a 3KB item size:
- Standard: 3WCUs
- Transactional: 6 WCUs
Consistency Model
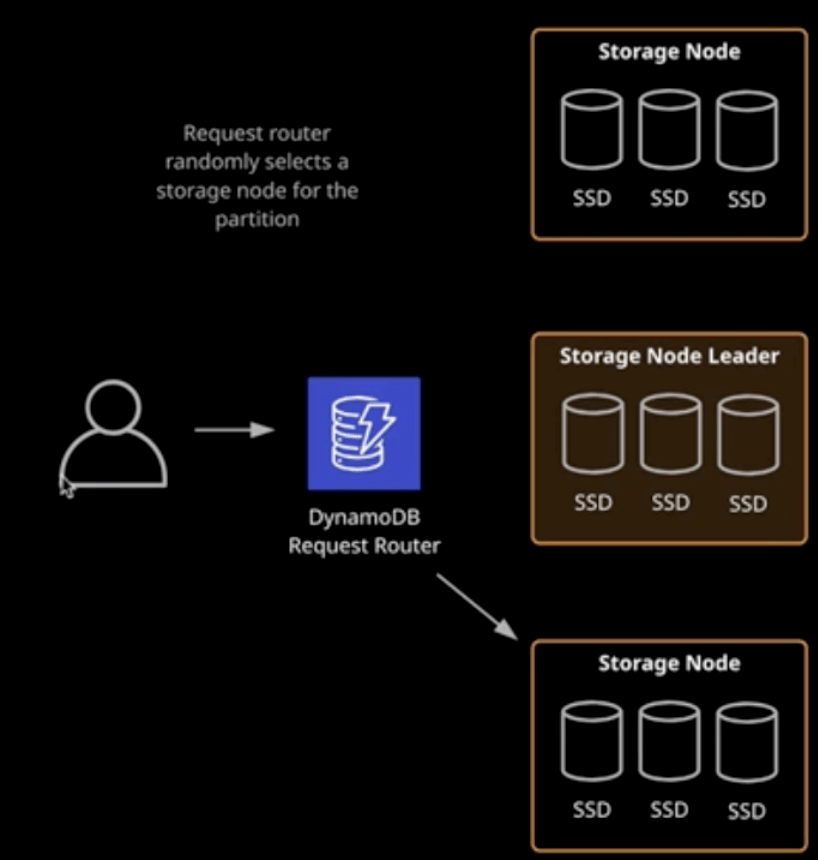
Below is the picture for getItem via DDB. one item can have 3 replicas cross 2 storage node, The DynamoDB Request Router will distribute getItem request to a random storage node, imaging the previous update action only applied in midle storage node(lead storage node), you’ll have 2/3 chance get the stale data(worst case), however if you use strongly consistent read, it require 2 of 3 matches cross replicas, that’s why eventually consistent reads are 50% the “cost” of strongly consistent.
Scan/Query
There are take away when choice between scan and query, that is use query when possible to avoid use scan, because query is much more efficiency than scan, you can only use scan when you’re pretty sure the table won’t going to be large and you do need most of items in that table.
Scan
- Returns all items and attributes for a given table
- Filtering results do not reduce RCU consuption; they simply discard data
- Eventually consistent by default, but the
consistentReadparameter can enable strongly consistent scans - Limit the number of items returned
- A single query returns results that fit within 1 MB
- Pagination can be used to improve performance
- Prefer query over scan when possible; occasional real-world use is okay
- If you are repeatedly using scans to filter on the same non-PK/SK attribute, consider creating a secondary index
Query
- Find items based on primary key values
- Query limited to PK, PK+SK or secondary indexes
- Requires PK attirbute
- Returns all items with that PK value
- Optional SK attribute and comparison operator to refine results
- Filtering results do not reduce RCU consuption; they simply discard data
- Eventually consistent by default, but the
ConsistentReadparameter can enable strongly consistent queries - Querying a partition only scans that one partition
- Limit the number of items returned
- A single query returns results that fit within 1 MB
- Pagination can be used to retrieve more than 1 MB
BatchGetItem/ BatchWriteItem
One thing keep in mind when use batch opration is it can using threading to opearte parallel, it was tested when operated 250 items batchGetItem can be 20 times faster than getItem

BatchGetItem
- Returns attributes for multiple items from multiple tables
- Request using primary key
- Returns up to 16 MB of data, up to 100 items
- Get unprocessed items exceeding limites via
UnprocessedKeys - Eventually consistent by default, but the
ConsistentReadparameter can enable strongly consistent scans - Retreives items in parallel to minimize latency
BatchWriteItem
- Puts or deletes multiple items in multiple tables
- Writes up to 16MB of data, up to 25 put or delete requests
- Get unprocessed items exceeding limits via
UnProcessedItems - Conditions are not supported for performance reasons
- Threading may be used to write items in parallel
DDB CURD
As for Java, DDB provide DynamoDBMapper to support annotation based data bind.
When Perform CRUD via DDB, Read/Write capacity is some thing need to keep notice. DynamoDB provide 2 types of Read/Write Capacity: Provisioned Capacity/On-Demand Capacity, On-demand capacity is good for new application which has unknown Read/Write requirement, after application running for a while, if the performance requried is become predictable, Provisioned Capacity is strongly recommended to save some money, in the mean time, DDB provide a auto scaling function to support scheduled scaling/throughput based scaling.
- Important: If your application exceed provisioned read/write capacity, your request will fail with an HTTP 400 code (
Bad Request) and aProvisionedThroughputExceededException. However The AWS SDKs have built-in support for retrying throttled requests, eventually it will failed after multi retires if it’s exceeded too much. Document found here.
Provisioned Capacity
- Minimum capacity required
- Able to set a budget(Maximum capacity)
- Subject to throtting
- Auto scanling available
- Risk of underprovisioning
- Lower price per API call
- $0.00065 per WCU-hour (us-east-1)
- $0.00013 per RCU-hour (us-east-1)
- $0.25 per GB-month (first 25GB is free)
On-Demand Capacity
- No minimum capacity: pay more per request than provisioned capacity
- Idle tables not charged for read/write, but only for storage and backups
- No capacity planning required
- Eliminates the tradeoffs of over - or under provisioning
- Use on-demand for new product launches
- Switch to provisioned once a steady state is reached
- $1.35 per milliion WCU (us-east-1)
- $0.25 per million RCU (us-east-1)
Auto Scaling
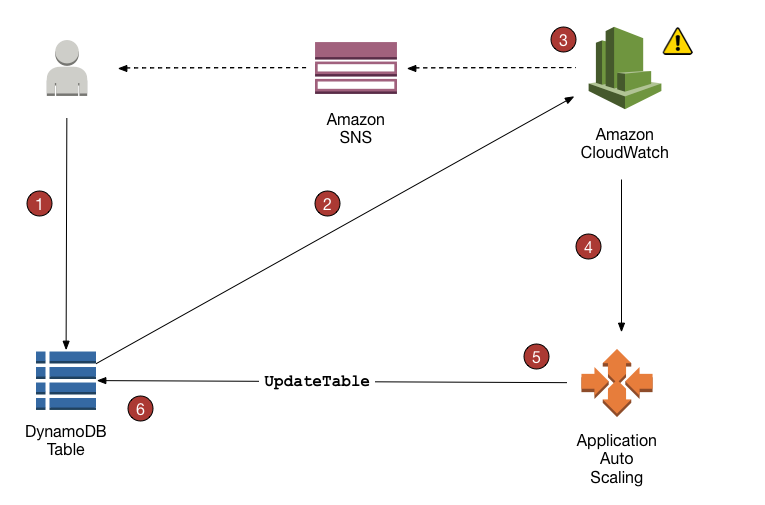
DynamoDB provide out of box auto scaling feature: https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/AutoScaling.html
Basiclly you can creat auto scaling configuration and when DDB table read/write capacity alarms(on cloud watch) goes off, it will trigger the auto scaling policy to scale up/down your table capacity. Optionally, you can confirg Cloudwatch alarm to trigger a SNS topic to send notification when scaling happen.
Secondary Index
Similar with Relational Database index, DynamoDB Secondary Index is a data structure that contains a subset of attributes from a table, along with an alternate key to support query operations. You can retrieve data from the index using a query, just like with a table. A table can have multiple secondary indexes.
There are 2 types of secondary index: GSI(Global Secondary Index) and LSI(Local Secondary Index), the mainly different is GSI only support eventualy consistency and LSI can provide strongly consistency, however LSI can only created when create table and has to use same partition key as the base table.
As you can see, GSI provides good flexibility to improve query/scan performance, however we still need to keep the number of indexes tto a minimum as it cost extra I/O and storage.
Transaction
Transaction enable developers to perform atomic writes and isolated reads with some limitation across multiple items and tables in same account same region. Both TransactWriteItems and TransactGetItems are up to 25 items or 4 MB, and may have transaction conflict errors.
DynamoDB perfroms 2 underlying reads or writes of every item in the transaction, one to prepare the transaction and one to commit the transaction.
TTL(Time to Live)
How it works
- TTL compares the current time to the defined TTL attribute of an item.
- If current time > item’s TTL value, then the item is marked for deletion.
- DynamoDB typically deletes expired items within 48hours of expiration.
- Items are removed from LSIs and GSIs automatically using an eventually consistent delete operation.
Due to the potential delay between expiration and deletion time, you might get expired items when you query for items, you need to use filter expression to return only items where the item’s TTL expiration > current time.
Global Table
A feature help customer create replication corss regions, quite slow but easy to use.
Encryption
- Encryption in transit uses HTTPS - by default
- Encryption at rest uses AWS KMS to encrypt all table data by default. You can use the default encryption, the AWS owned customer master key (CMK), or the AWS managed CMK to encrypt all your data.
- Encryption Client when use client libraries. - optional
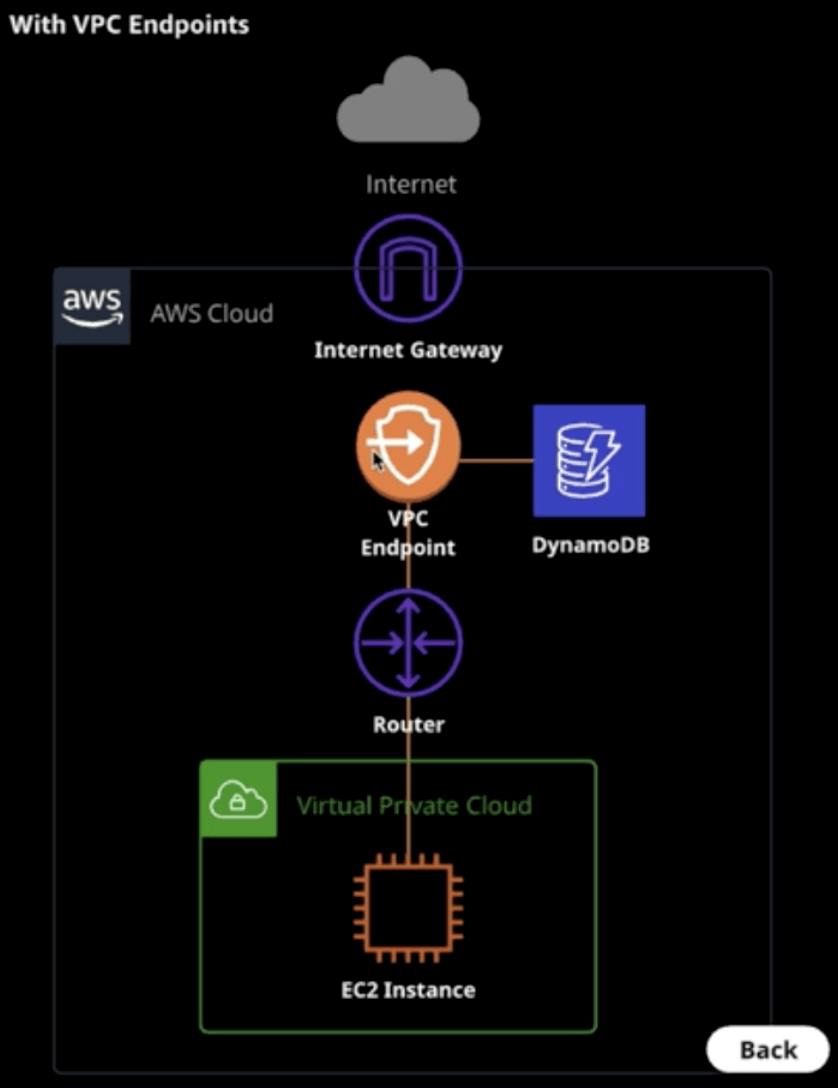
VPC Endpoint
Connect EC2 instance with DDB table without public internet expose - no additional charge.
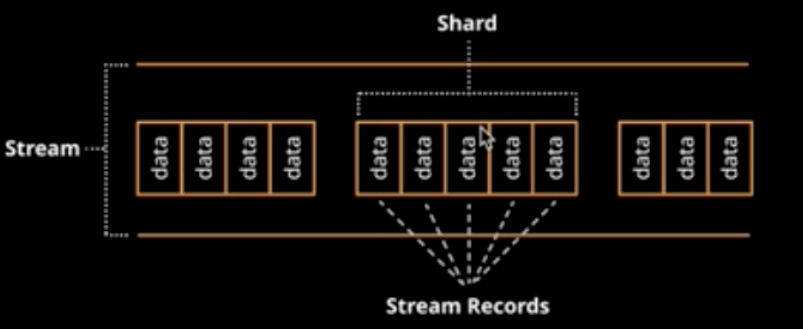
Stream
What are DynamoDB Streams?
- Time-ordered sequence of item-level changes in a table
- Partitioned change log(shards) allows scaling
- Information stored for 24 hours
- Provides a stream of inserts, update, and deletes
- Stream records appear in the same sequence as the item modifications
- Guaranteed to be delivered only once
- Use Kinesis Client Library(KCL), Lambda, or the API to query changes
- KEYS_ONLY: Only the Key attributes of the modified item
- NEW_IMAGE: The entire item, as it appears after it was modified
- OLD_IMAGE: The entire item, as it appears before it was modified
- NEW_AND_OLD_IMAGES: Both the new and old images of the item
- Eeach GetREcords API call consumes 1 streams read request unit (not RCU) and returns up to 1MB of data
- The first 2.5 M stream read requests units are free, $0.02 per 100k reads thereafter
General speaking, you can use DynamoDB modification event trigger a lambda and do whatever you want, and you can configure a period of event collection to be triggered only once, and get the event collection of this period of time. There’re some user scenarios are suitable:
- Corss-region replication (global tables)
- Establish relationship acorss table
- Messaging/notifications
- Aggregation/filtering
- Analytical reporting
- Archiving and auditing
DAX(DynamoDB Accelerator)
In memory cache for read, delivers up to 10 times performance improvement, compatible with DDB API calls, easy to config.
SQS Write Buffer
A write cache by SQS + Lamdba to make sure customer don’t lose data even DDB becomes unavailable.
Security
AWS IAM provide attributed based access control, DDB provide a feature to generate strict policy.
AWS CloudTrail provide trail to support DDB api operation log except scan/query, log can go to either S3 bucket or SNS.




