 Luke.Du's blog
Luke.Du's blog
Metrics are vital for the distribution system, this article describes how to implement a metric function for a high TPS system.
The code can be found here: https://github.com/ADU-21/producer-consumer
Requirements
Our server has 3k~5k TPS per host, and the minimum time unit of metrics is 1 minute. The metric service load is much smaller compared to our server, so we want to minimize the number and size of requests to emit metrics.
In terms of performance, we don’t want the metric collection to slow down our service traffic, and the metric function should consume system resources (CPU, memory) as less as possible.
From the extensibility perspective, we want this function to accept different metrics types and connect to the different metric systems(local/remote).
Problem breakdown
Because we don’t want the metric collection process to block the real-time transaction, it has to be an asynchronous model. Given the speed to collect metric to the memory is inconsistent with emitting to metric service, we can use Producer-consumer pattern to solve this problem. Before completely adopting this solution, here are few more decisions we need to make:
Blocking Queue or Non-Blocking Queue
The classical producer-consumer pattern is using a bounded blocking queue as a buffer of the foreground tasks because it’s thread-safe and we don’t want to lose any task. There is a potential problem here: When the queue was full, it will block the enqueue process and lead to a significant latency increase which is unacceptable, we would rather discard some metrics than block service traffic.
Thus, we need to replace the blocking queue with a thread-safe non-blocking queue, ConcurrentLinkedQueue is our choice, it’s an unbounded FIFO queue implemented by a single-direction linked node (refer to my previous blog), and it’s lock-free because of using CAS(Compare and Swap) so it has better performance compare to blocking queue with locks.
However, we still want this queue to have a limited size to protect our memory cost, but due to the nature of the linked node, the size() function requires O(N) time complexity to travel every node. The solution is to use a Semaphore to track the size of the queue:
- The number of permits is always the same as the length of the queue.
- When enqueue, check the number of available permits is not greater than MAX_SIZE;
- After enqueue succeeds, release permit.
- When dequeue(drain queue), drain the permits as well.
- The semaphore can be used to block the background task in order to save some CPU by using the
acquireUninterruptibly()method.
Observer
Let’s look at the producer side. It’s responsible for enqueueing different types of metrics without impacting business logic, so I’m calling it Observer, we can have different classes of Observer holding different metadata and different ways of constructing metrics.
Distributor
The distributor is the service holding the non-blocking queue, it provides a enqueue function to the observers, and the dequeue function was triggered by a single scheduled thread, we want all metrics in a unit of time to be aggregated in the consumption process, so we drain all permits and poll all items from the queue and pass to consumers.
Consumer
The Consumer aggregates metrics to key-value pairs and regularly sends aggregated metrics to the metric server. We might have different ways to aggregate metrics so we can have different types of counters in consumers. Because we emit metrics in chronological order, we need another scheduled thread to send the call to the remote server. Having a jitter in the scheduled thread is important because we don’t want hundreds of thousands of hosts to send metrics to the metric server and create regular spikes.
Counter
Because the aggregate metrics can be drained during the update, there is another potential concurrency issue. We need to either use a thread-safe data structure or have a lock on the counter. My choice is to use a HashMap with synchronized lock on the counter itself, here are some weights up:
ConcurrentHashMapis using segment lock(extended ReentrantLock) which has better performance than HashTable, but it can’t guarantee map won’t change during metrics drain.HashTableprovides all thread-safe operations, The only problem is during the draining process, we need to read before cleaning the map, those 2 operations are atomic but they’re not atomic together. Thus we need a lock for the counter.- With a
synchronizedlock on the counter, the map doesn’t have to be thread-safe, so we can use the most efficient map -HashMap.
Solution
Now, we’re having a process like this:
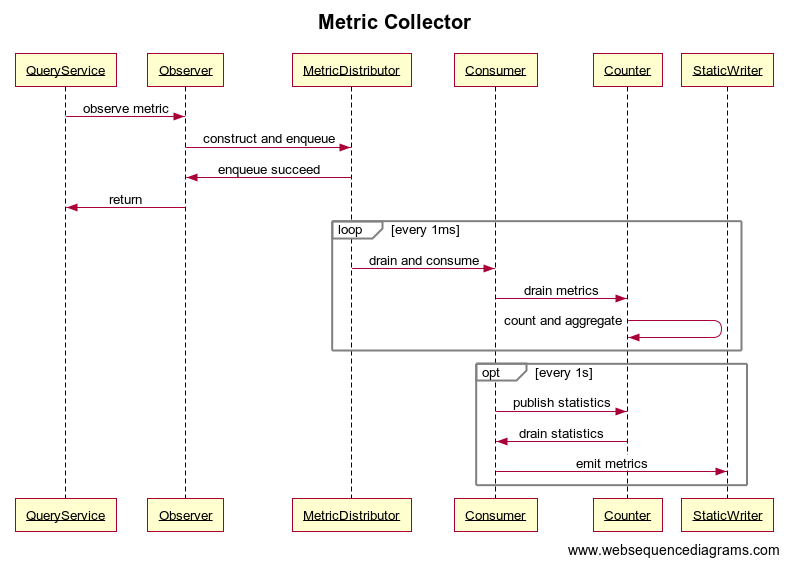
I’m using static writer to replace metric service and changed publish frequency from 1 minute to 1 second to have a timely response.
The complete code can be found here: https://github.com/ADU-21/producer-consumer




