 Luke.Du's blog
Luke.Du's blog
In Computer Systems, the CPU is much faster than the storage system, so ideally we want storage system read/write as fast as possible, unfortunately, the price of storage media increases exponentially with the access speed. Thus, in order to balance cost and performance, we designed a multi-layer memory hierarchy.
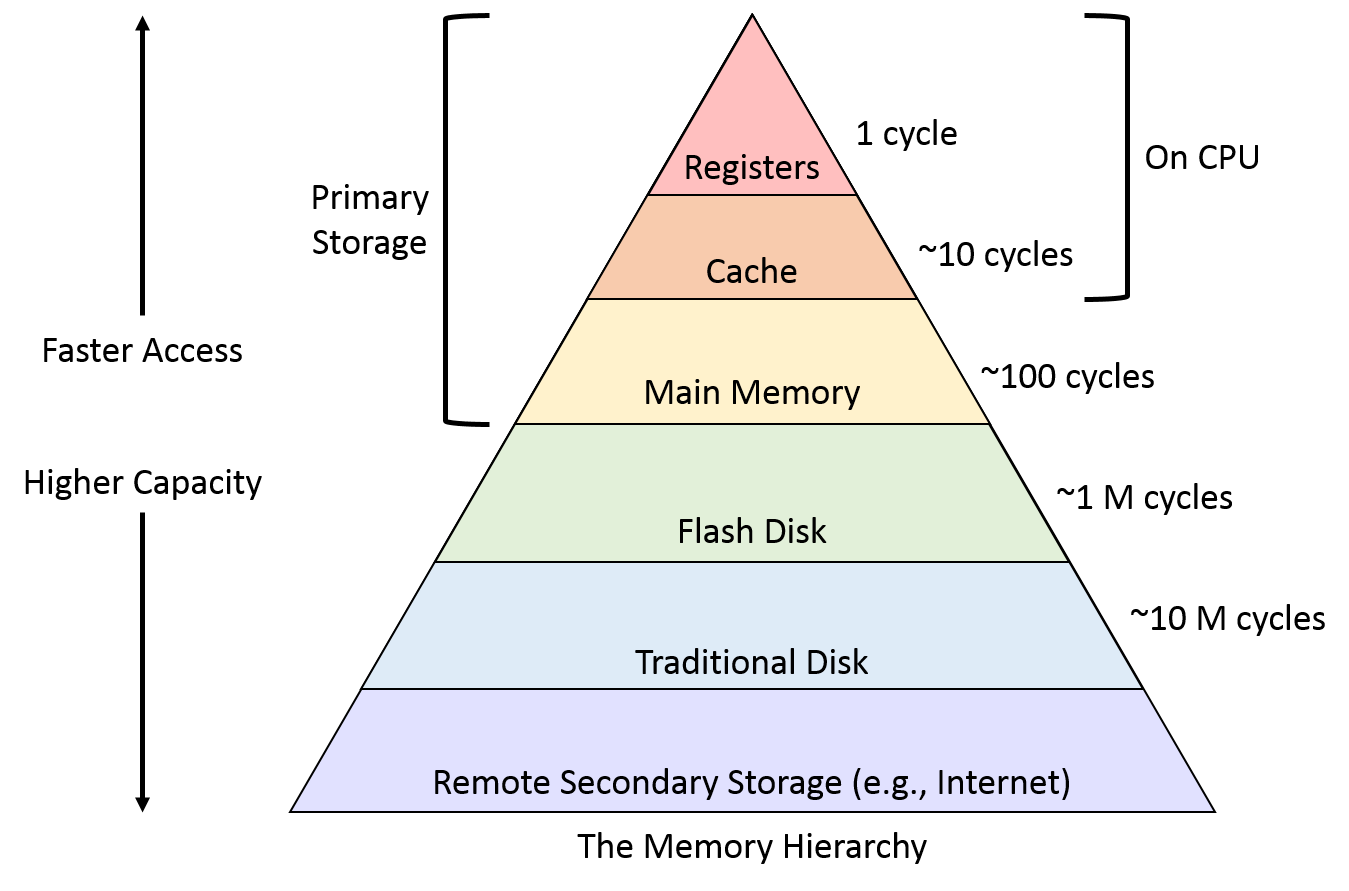
Primary Memory
The primary memory is also known as internal memory, it is accessible by the CPU processor straightly. This memory includes the main memory, cache, as well as CPU registers.
CPU
The fastest memory is in the CPU, and the fastest in the fastest is Processor Register. then there is a multi-layer CPU cache, normally referring to L1/L2/L3 cache, the L1 cache provides 0.5ns reference time, L2 cache reference is 5ns per time.
Main Memory
Main memory is a physical device that provides fast read/write at a reasonable price. the reference time of the main memory is 100ns(20x L2 cache) per time. read 1 MB sequentially from memory can takes 250us.
Secondary Memory
The secondary memory is also known as external memory, including but not limited to magnetic disk, SSD. It is accessible by the CPU processor through an input/output module. Read 1 MB sequentially from SSD can take 1ms (4x memory), read 1 MB sequentially from a magnetic disk can take 20ms(20x SSD)
Contiguous Memory Allocator(CMA)
Contiguous memory allocation is a classical memory allocation model, it’s been widely used from 1960s to 1970s.
Fixed Partitioning
The earliest and one of the simplest techniques which can be used to load more than one process into the main memory.
The main memory is divided into partitions of equal or different sizes. The operating system always resides in the first partition while the other partitions can be used to store user processes. The memory is assigned to the processes in a contiguous way.
Dynamic Partitioning
Dynamic partitioning’s partition size is not declared initially. It is declared at the time of process loading. The size of each partition is equal to the size of the process.
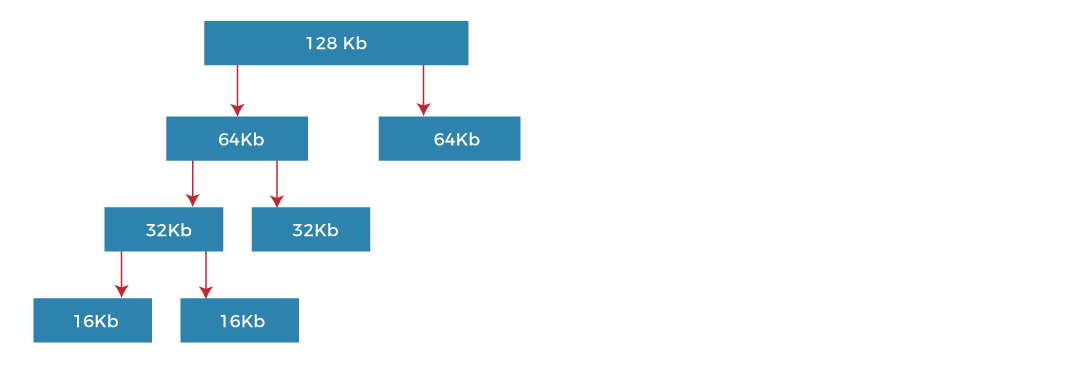
Buddy System
Fixed partition limited degree of multiprogramming, and has low memory utilization; Dynamic partition’s algorithm is complex, and the cost of recycling idle partitions is high. Buddy System is a compromise between the two methods.
The buddy system manages memory in the power of two increments. Assuming the memory size is 2^k, suppose a size of M is required.
- If 2^(k-1)< M <= 2^k: Allocate the whole block
- Else: Recursively divide the block equally and test the condition at each time, when it satisfies, allocate the block and get out of the loop.
The system also keeps a record of all the unallocated blocks and can merge these different size blocks to make one big chunk.
Paging
The continuous memory allocations generate fragments, although this can be removed by compaction, which cost too much. We need a discrete way to allocate memory so we don’t have to “compact”, now let’s talk about paging.
Page and Frame
The main idea behind the paging is to divide each process into the form of pages. The main memory will also be divided into the form of frames. One page of the process is to be stored in one of the frames of the memory. The pages can be stored at different locations of the memory but the priority is always to find the contiguous frames or holes.
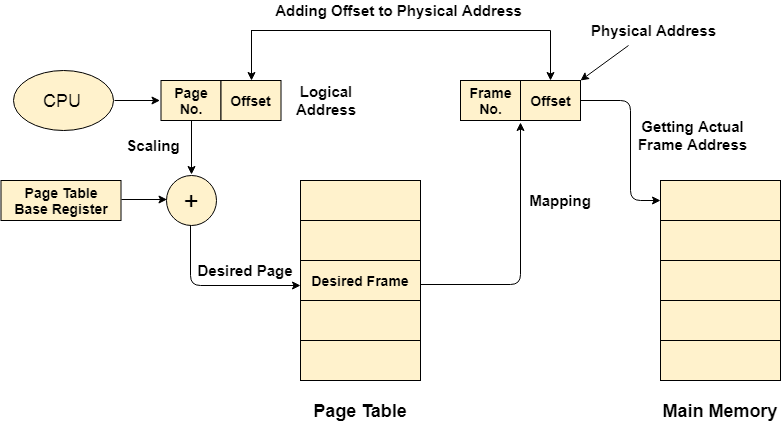
Memory Management Unit (MMU)
The purpose of the MMU is to convert the logical address into a physical address. The logical address is the address generated by the CPU for every page of the processes while the physical address is the actual address of the frame where each page will be stored.
The logical address has two parts: Page Number and Offset, when a page is to be accessed by the CPU, the operating system needs to obtain the physical address by converting the page number of the logical address to the frame number of the physical address. The offset remains the same in both addresses.
Word is the smallest unit of memory. It is a collection of bytes. Every operating system defines different word sizes after analyzing the n-bit address that is inputted to the decoder and the 2 ^ n memory locations that are produced from the decoder.
Page Table
MMU is used to map logical addresses to physical addresses, Page table is the data structure to store MMUs for a process.
The page tables are stored in the main memory, in the CPU there is a Page-Table Base Register(PTBR) which stores the page table’s initial address and length. When the process was not running the page’s address info is stored in PCB, when the process is running, that info will be loaded into PTBR, this process is called scaling. A single-core CPU only requires a single PTBR to run multiple processes.
Page Table Entry
Along with the page frame number and offset, the page table also contains some of the bits representing the extra information regarding the page, for read/write control, reference, caching, or other purposes.
Transaction Lookaside Buffer(TLB)
TLB is a memory cache that stores the recent translations of the page table entries, it is used to reduce the time taken to access a user memory location. It’s implemented as a Least Recently Used (LRU) cache in the chip’s MMU.
Multi-level page table
In modern OS the page table can be very large, for a page table that size is greater than the frame size, we can store the page table in a collection of frames, and use an Outer Page Table to manage those frames. It’s also known as Hierarchical paging.
All levels of page tables are stored in main memory, and only Level1(single page table)’s address is stored in PTBR, when MMU tries to get the physical address by logical address, it requires multi-memory access for each level table, this process can speed up by TLB.
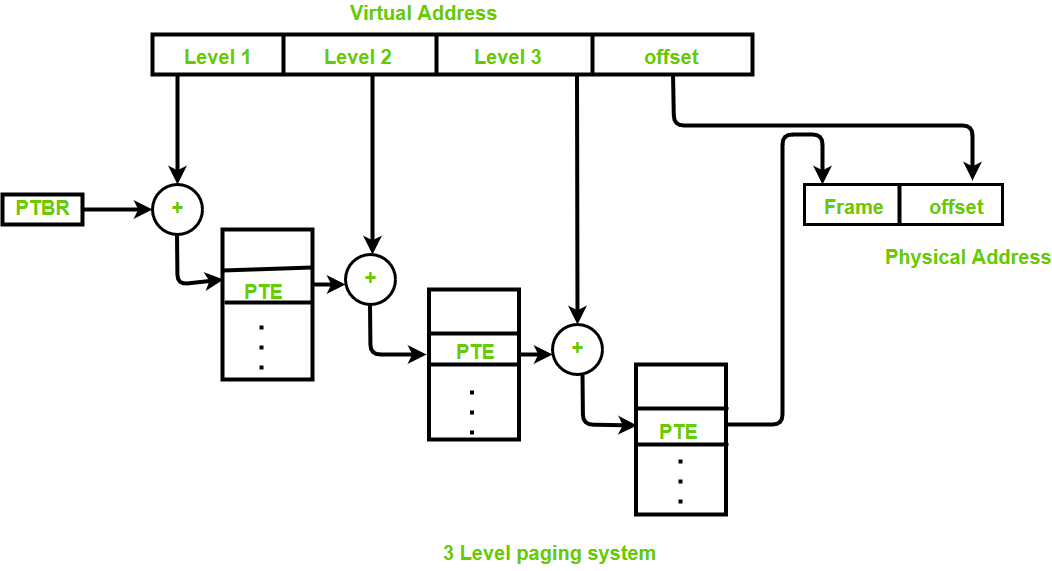
Generally, the page table size will be equal to the size of the page.
Number of entries in page table:
= (virtual address space size) / (page size)
= Number of pages
Segmentation
Paging is more close to the Operating system rather than the User. It divides all the processes into the form of pages regardless of the fact that a process can have some relative parts of functions that need to be loaded in the same page. It decreases the efficiency of the system. Segmentation is more friendly to programmers, it divides the process into segments. Each segment contains the same type of functions such as the main function can be included in one segment and the library functions can be included in the other segment.
The details about each segment are stored in a table called the segment table, each segment entry contains 2 parts:
- Base: Base address of the segment.
- Limit: Length of the segment.
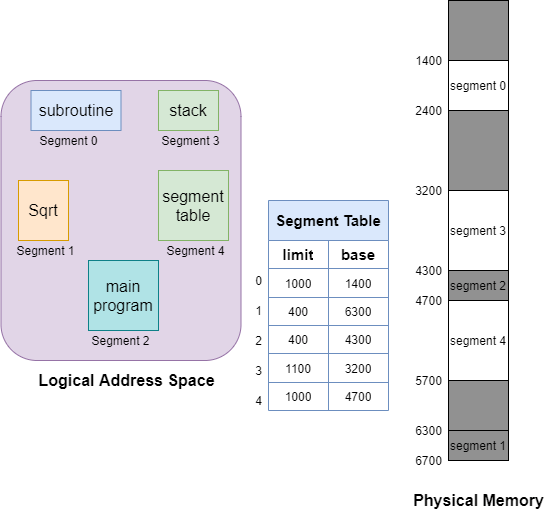
There are 2 types of segmentation: Virtual memory segmentation and Simple segmentation, the key difference is virtual segments do not necessarily have to be located in memory at any point in time, however, the simple segments do.
Translation of Logical address into physical address by segment table
CPU generates a logical address that contains two parts:
- Segment Number: Index of segment entry in the table.
- Segment Offset: It must lie between
0and thesegment limit. If the Offset exceeds the segment limit then the trap is generated.
Correct offset + Segment base = Address in Physical memory
![]()
Segmentation is another expensive memory management algorithm, it solved some problems like no internal fragments and smaller tables causing less overhead, but it also has some problems: as processes are loaded and removed from the memory, the free memory space is broken into little pieces, causing external fragmentation.
Segmented Paging
Paging provides good memory utilization, Segmentation is more user-friendly. They can be combined together to get the best features out of both techniques, this is called Segmented Paging.
In Segmented Paging, the main memory is divided into variable-size segments, and then further divided into fixed-size pages. In the segmented paging table, there are 3 properties for each entry:
- Segment Number: Point to the segment.
- Page Number: Points to the page within the segment.
- Page Offset: Offset within the page frame.
When translating a logical address into a physical address, requires access to the main memory 3 times, this process can also speed up by TLB.
- Get the page table’s initial address from the segment table by
segment number. - Get the frame number from the page table by
page number, combine it withpage offset, and become the physical address. (no fragment offset needed). - Read data by
physical address.
![]()
Virtual Memory
Today’s programs mostly rely on large memories, when RAM memory is not enough, we can extend the main memory by swapping data that has not been used recently over to secondary memory(disk), the physical address in different devices mapping into the same virtual address, so from OS perspective we’re having much larger memory space without purchase hardware devices, and this can increase degrees of multiprogramming and CPU utilization.
It is a technique that is implemented using both hardware and software. It maps virtual addresses into physical addresses in computer memory.
- All memory references within a process are
logical addressesthat are dynamically translated intophysical addressesat run time. This means that a process can beswapped inandoutof the main memory such that it occupies different places in the main memory at different times during the course of execution. - A process may be broken into a number of pieces and these pieces need not be continuously located in the main memory during execution. The combination of dynamic run-time address translation and use of
pageorsegment tablepermits this.
Demand Paging
The process of loading the page into memory on demand (whenever page fault occurs) is known as demand paging.
Swapping
Swapping a process out means removing all of its pages from memory, or marking them so that they will be removed by the normal page replacement process.
Thrashing
We should not overly rely on virtual memory, since it’s considerably slower than RAM, if the OS has to swap data between virtual memory and RAM too often, the computer will begin to slow down - it is called thrashing.
There are 2 causes of Thrashing:
- High degree of multiprogramming.
- Lack of Rames.
To prevent thrashing we can instruct the long-term scheduler not to bring the processes into memory after the threshold. if thrashing already happened, we can use mid-term scheduler to swap out some processes, which can help to recover.




